Hi everybody.
My English not good, im from VietNam
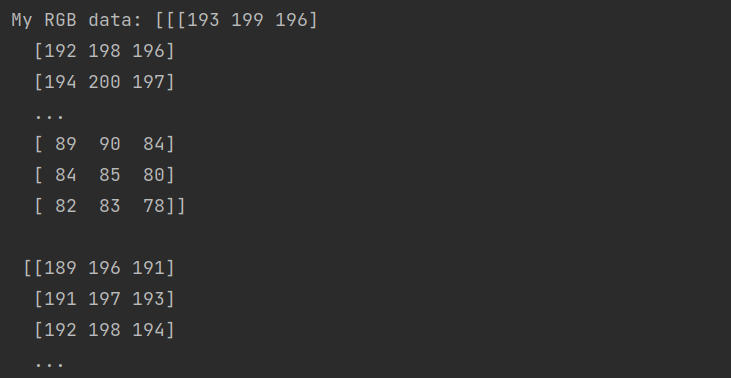
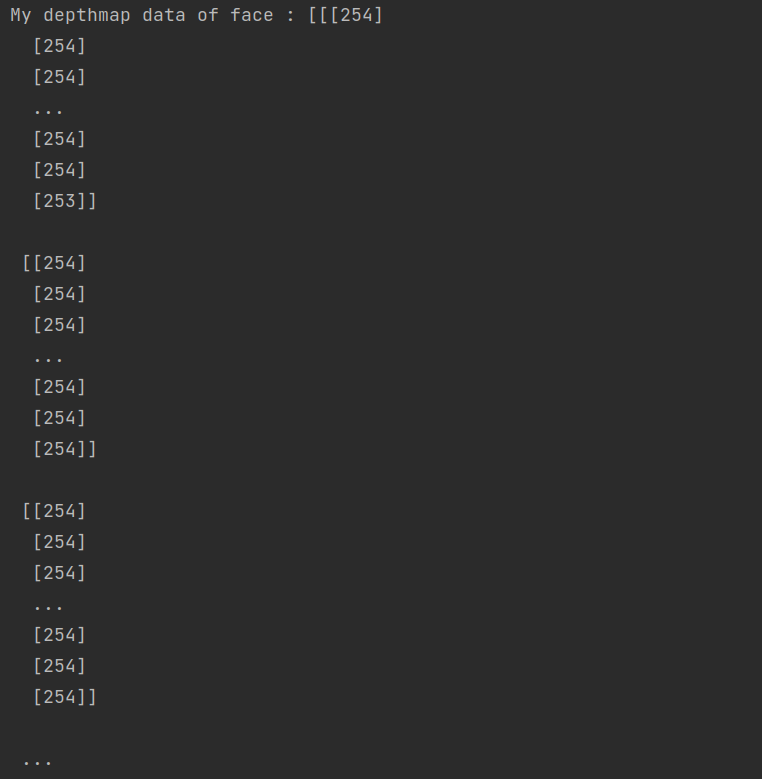
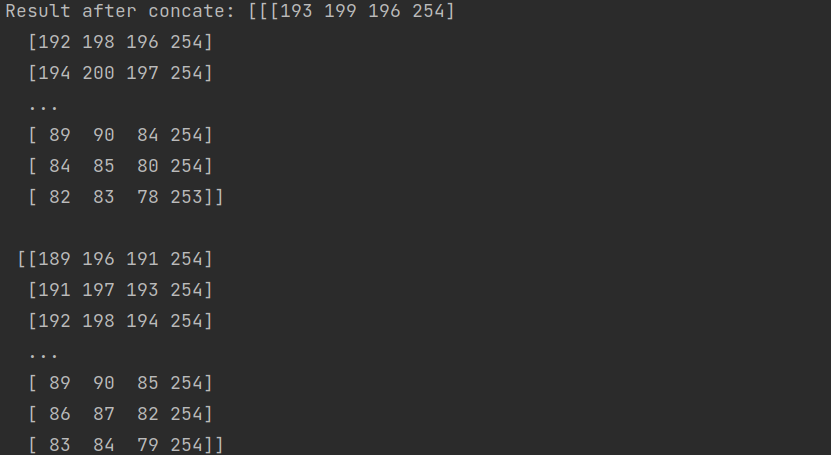
I tried change input chanels to inception recive input 4 channel (mycode below) with one picture .png and depth information .npy, I get error
My code:
def Inception(in_planes, out_planes, pretrained=False):
if pretrained is True:
model = models.inception_v3(pretrained=True)
print("Pretrained model is loaded")
else:
model = models.inception_v3(pretrained=False)
if in_planes == 4:
model.Conv2d_1a_3x3.conv=nn.Conv2d(4, 64, kernel_size=3, stride=2, padding=2, bias=False)
nn.init.kaiming_normal_(model.Conv2d_1a_3x3.conv.weight, mode='fan_out', nonlinearity='relu')
# Parameters of newly constructed modules have requires_grad=True by default
model.fc = nn.Linear(model.fc.in_features, out_planes)
return model
My error:
Traceback (most recent call last):
File "train_softmax.py", line 307, in <module>
pretrained_optim_path=args.pretrained_optim_path)
File "train_softmax.py", line 155, in train_model
outputs,aux_outputs = model(inputs)
File "/home/viet/anaconda3/envs/pythonProject11/lib/python3.7/site-packages/torch/nn/modules/module.py", line 541, in __call__
result = self.forward(*input, **kwargs)
File "/home/viet/anaconda3/envs/pythonProject11/lib/python3.7/site-packages/torchvision/models/inception.py", line 101, in forward
x = self.Conv2d_1a_3x3(x)
File "/home/viet/anaconda3/envs/pythonProject11/lib/python3.7/site-packages/torch/nn/modules/module.py", line 541, in __call__
result = self.forward(*input, **kwargs)
File "/home/viet/anaconda3/envs/pythonProject11/lib/python3.7/site-packages/torchvision/models/inception.py", line 352, in forward
x = self.conv(x)
File "/home/viet/anaconda3/envs/pythonProject11/lib/python3.7/site-packages/torch/nn/modules/module.py", line 541, in __call__
result = self.forward(*input, **kwargs)
File "/home/viet/anaconda3/envs/pythonProject11/lib/python3.7/site-packages/torch/nn/modules/conv.py", line 345, in forward
return self.conv2d_forward(input, self.weight)
File "/home/viet/anaconda3/envs/pythonProject11/lib/python3.7/site-packages/torch/nn/modules/conv.py", line 342, in conv2d_forward
self.padding, self.dilation, self.groups)
RuntimeError: Given groups=1, weight of size 64 4 3 3, expected input[16, 3, 299, 299] to have 4 channels, but got 3 channels instead
0%|
My input is one picture .PNG and one .NPY file. I concate and tranform to tensor.
Please help me.