Here is the dropbox link to the zip containing log file, model.py, handler.py etc.
https://www.dropbox.com/s/gi8wmyxmpy1zx84/Files.zip?dl=0
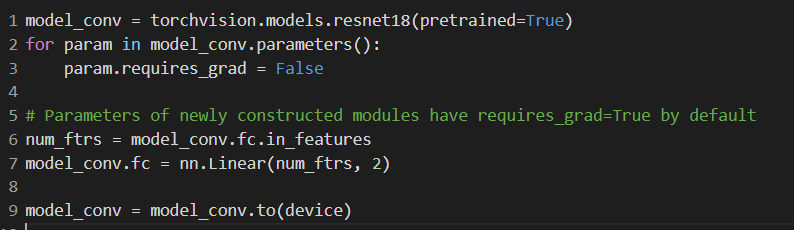
Model trained:
Commands used:
torch-model-archiver --model-name foodnet_resnet18 \
--version 1.0 \
--model-file model/model.py \
--serialized-file model/foodnet_resnet18.pth \
--handler model/handler.py \
--extra-files model/index_to_name.json
torchserve --start \
--ncs \
--ts-config deployment/config.properties \
--model-store deployment/model-store \
--models foodnet=foodnet_resnet18.mar
What kind of error are you seeing? Could you post the complete stack trace, please?
Could you please check out the log file from the dropbox link? The webpage isn’t allowing me to post a complete stack trace.
@ptrblck ,
I’ve traced the error to model.load_state_dict( ). To give you context,
import torch.nn as nn
from torchvision.models.resnet import ResNet,BasicBlock
class ImageClassifier(ResNet):
def __init__(self):
super(ImageClassifier,self).__init__(BasicBlock,[2,2,2,2],num_classes=2)
self.fc = nn.Linear(512,2)
import torch
model = ImageClassifier()
model.load_state_dict(torch.load("trainedRes18.pth"))
I’ve trained and saved the “trainedRes18.pth” using:
The code snippet I’ve posted.
torch.save(model_ft.state_dict(),"trainedRes18.pth")
I’m not familiar enough with the torchserve backend, and don’t know why the loading is failing as it doesn’t seem to provide enough information in the error message (i.e. is the file missing?).
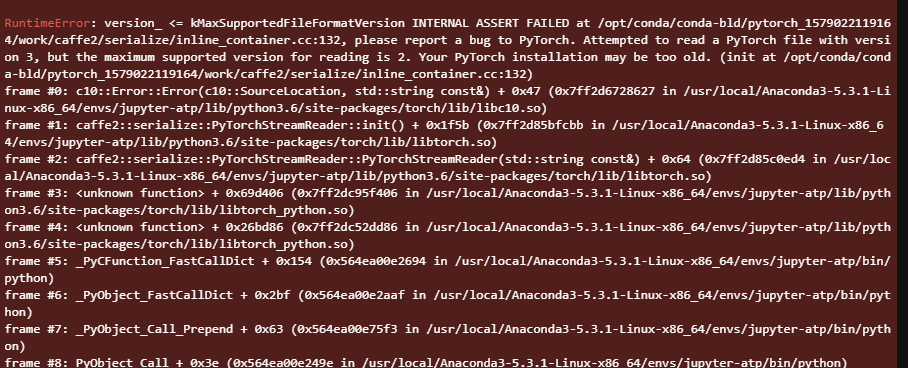
I’ve tried to run the load separately to see why its failing. This is what it shows.
That’s more helpful and points towards a PyTorch version, which is too old to load the file.
I guess you might have stored the state_dict (or any other file) using a new PyTorch release and are trying to load it in torchserve using an older PyTorch version.
Could this be the case and if so, could you update torchserve to the latest release?
The torch version on which I am running the torchserve is:
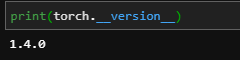 cpu only.
cpu only.
And I’ve trained the model using torch 1.8.0+cu101
That would explain the error. Could you update the PyTorch version in your torchserve environment to 1.8.0 as well?
After updating PyTorch, model load is working but only if map_location is used. How do I make torchserve know that it needs to load model on cpu and not on gpu?
The loading behavior is not defined by torchserve but by PyTorch depending how you’ve stored the state_dict. You could either push the model to the CPU before storing the state_dict or use the map_location argument as explained here.
1 Like