Hello,
Could smn please help me to understand how can I fix my code. I’m doing a QAT training of ResNet50 and encountering an error in one of the convoluational layers:
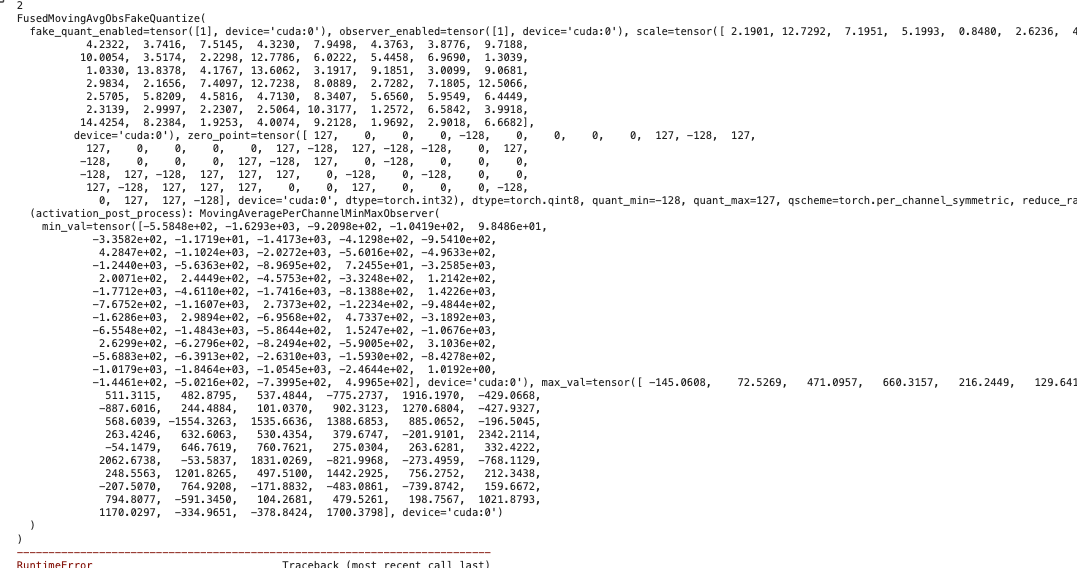
RuntimeError:
zero_pointmust be betweenquant_minandquant_max
Code is relatively simple.
from torchvision.models import resnet50, ResNet50_Weights
from torch.ao.quantization import (
fuse_modules,
QuantWrapper,
get_default_qat_qconfig)
qconfig = get_default_qat_qconfig('fbgemm')
def apply_recursive(model, qconfig):
model.qconfig = qconfig
# qconfig should be applied to all children
for name, module in model.named_children():
apply_recursive(module, qconfig)
return model
def get_qat_fused_manual():
model_fp32 = resnet50(weights=ResNet50_Weights.IMAGENET1K_V2)
model_fp32.eval()
model_fp32 = apply_recursive(model_fp32, qconfig)
# fuse layers
fuse_modules(model_fp32,[['conv1', 'bn1', 'relu']], inplace=True)
for layer in ['layer1','layer2','layer3', 'layer4']:
module = model_fp32.get_submodule(layer)
n_iter = len(module)
for i in range(n_iter):
submodule = module.get_submodule(str(i))
fuse_modules(submodule,[['conv1', 'bn1'], ['conv2', 'bn2'], ['conv3', 'bn3', 'relu']], inplace=True)
# replace in downsample
for name, m in submodule.named_children():
if name == 'downsample':
fuse_modules(submodule,[['downsample.0', 'downsample.1']], inplace=True)
model_fused = model_fp32
model_fused = QuantWrapper(model_fp32)
model_fused = torch.ao.quantization.prepare_qat(model_fused.train())
return model_fused
qat_model = get_qat_fused_manual()
data_loader_train = torch.utils.data.DataLoader(
dataset_train,
batch_size = 32,
sampler=val_sampler,
num_workers=args.workers
)
device = 'cuda'
parameters = qat_model.parameters()
criterion = torch.nn.CrossEntropyLoss(label_smoothing=0)
optimizer = torch.optim.SGD(
parameters,
lr=1e-5,
momentum=0.9,
# weight_decay=args.weight_decay,
nesterov="nesterov"
)
qat_model.to(device)
qat_model.train()
for iter, (image, target) in enumerate(data_loader_train):
print (iter)
image, target = image.to(device), target.to(device)
output = qat_model(image)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
From what I see the training is happening for several iterations and then the model.forward method triggers an error
/usr/local/lib/python3.10/dist-packages/torch/ao/quantization/stubs.py in forward(self, X)
61 def forward(self, X):
62 X = self.quant(X)
---> 63 X = self.module(X)
64 return self.dequant(X)
....
/usr/local/lib/python3.10/dist-packages/torchvision/models/resnet.py in _forward_impl(self, x)
266 def _forward_impl(self, x: Tensor) -> Tensor:
267 # See note [TorchScript super()]
--> 268 x = self.conv1(x)
269 x = self.bn1(x)
270 x = self.relu(x)
...
/usr/local/lib/python3.10/dist-packages/torch/ao/quantization/fake_quantize.py in forward(self, X)
351
352 def forward(self, X: torch.Tensor) -> torch.Tensor:
--> 353 return torch.fused_moving_avg_obs_fake_quant(
354 X,
355 self.observer_enabled,
RuntimeError: `zero_point` must be between `quant_min` and `quant_max`.
So could anyone point me what is the problem here? Unable to find anything related on the internet.
Thank you.