``class Autoencoder(nn.Module):
def init(self):
super(Autoencoder, self).init()
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, 3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(16, 32, 3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(32, 64, 3)
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(64, 32, 3),
nn.ReLU(),
nn.ConvTranspose2d(32, 16, 3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.ConvTranspose2d(16, 1, 3, stride=2, padding=1, output_padding=1),
nn.Sigmoid()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x`
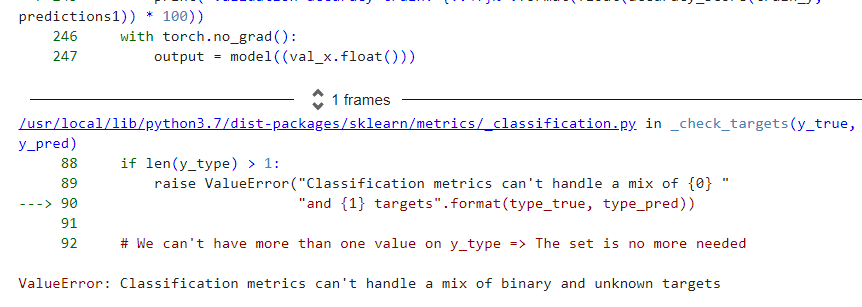
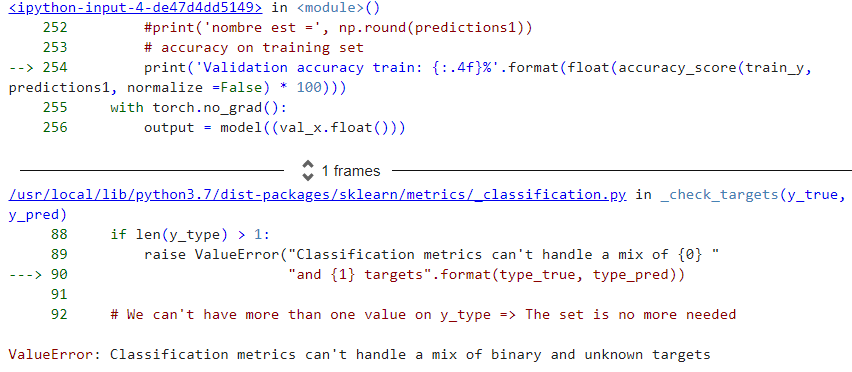
the error in loss_train = criterion(output_train, y_train.long())
RuntimeError: only batches of spatial targets supported (3D tensors) but got targets of dimension: 1