So I’ve been around the use of complex NNs in pytorch for a while, and I’m trying to implement a custom working version based on some available code online that works for complex-valued data. The purpose is to build a AE that accepts complex-valued data (EM type of data) and trains the NN accordingly. Unfortunately I cannot seem to bypass this issue and it seems that I’m stuck into a weird dtype mistake (I convert everything to complex dtype tho).
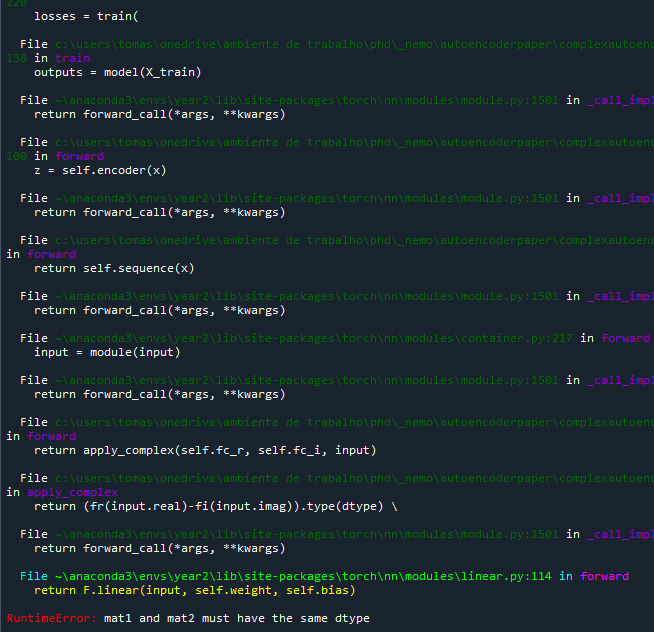
Any chance any of the complex experts can give me a hand @ptrblck , @albanD , @mruberry , @anjali411 ?
Code
import numpy as np
import sys
import matplotlib.pyplot as plt
import numpy as np
from torch import nn
from torch import optim
import torch
from scipy.io import loadmat
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import os
from torch import nn
from torch import optim
import torch
import torch.nn.functional as F
Tensor = torch.Tensor
import math
def complex_relu(input):
return F.relu(input.real).type(torch.complex128)+1j*F.relu(input.imag).type(torch.complex128)
def apply_complex(fr, fi, input, dtype = torch.complex128):
return (fr(input.real)-fi(input.imag)).type(dtype) \
+ 1j*(fr(input.imag)+fi(input.real)).type(dtype)
class ComplexReLU(nn.Module):
def forward(self,input):
return complex_relu(input)
class ComplexLinear(nn.Module):
def __init__(self, in_features, out_features):
super(ComplexLinear, self).__init__()
self.fc_r = nn.Linear(in_features, out_features)
self.fc_i = nn.Linear(in_features, out_features)
def forward(self, input):
print('complex applied')
return apply_complex(self.fc_r, self.fc_i, input)
class ComplexMSELoss(nn.Module):
def __init__(self):
super(ComplexMSELoss, self).__init__()
def forward(self, inputs, targets):
if inputs.is_complex():
print('is complex!')
return torch.mean((inputs - targets).pow(2))# Compute mean squared error between real and imaginary components
else:
print(inputs.dtype)
return F.mse_loss(inputs , targets)
class MLP(nn.Module):
def __init__(self, layer_io, activation = nn.ReLU() ):
super(MLP,self).__init__()
layers_list = []
for i,o in layer_io:
print('ssss')
#layers_list.extend([ nn.Linear(i,o), activation])
layers_list.extend([ ComplexLinear(i,o), activation])
self.sequence = nn.Sequential(*layers_list)
def forward(self, x):
return self.sequence(x)
class Autoencoder(nn.Module):
def __init__(self,
latent_size=14,
encoder_dims=[32,32],
decoder_dims=[32,32],
input_size=64,
activation = nn.ReLU()
):
super(Autoencoder,self).__init__()
self.encoder = MLP(
layer_io = zip([input_size]+encoder_dims, encoder_dims+[latent_size]),
activation = activation)
self.decoder = MLP(
layer_io = zip([latent_size]+decoder_dims[:-1], decoder_dims),
activation = activation)
self.head = ComplexLinear(decoder_dims[-1], input_size)#nn.Linear(decoder_dims[-1], input_size)
def forward(self, x):
#print(x.dtype)
z = self.encoder(x)
print('get here')
reconstructed = self.head(
self.decoder(z))
return reconstructed
def train(model,X_train_noisy, X_test,epochs=20000,lr=4e-3):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)#move data to gpu if available
X_train = totensor(X_train_noisy)#clone numpy data to torch tensor
X_test = totensor(X_test)#clone numpy data to torch tensor
optimizer = optim.Adam(model.parameters(), lr=lr)
#CosineAnnealingLR is a scheduling technique that starts with a very large learning rate and then aggressively decreases
#it to a value near 0 before increasing the learning rate again
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, epochs-1, eta_min=1e-8)
criterion = ComplexMSELoss()#nn.MSELoss()
losses=[]
valid_accs=[]
model.train()
for epoch in range(epochs):
print('Training epoch {}'.format(epoch))
# reset the gradients back to zero
# PyTorch accumulates gradients on subsequent backward passes
optimizer.zero_grad()
# compute reconstructions
print(X_train.dtype)
outputs = model(X_train)
print('yes')
print(outputs.dtype)
# compute training reconstruction loss
train_loss = criterion(outputs, X_train)
#print('Training loss: %.4f' % (mean_loss))
# compute accumulated gradients
train_loss.backward()
# perform parameter update based on current gradients
optimizer.step()
scheduler.step()
# add the mini-batch training loss to epoch loss
loss = train_loss.item()
losses.append(loss)
#Check epoch MSE
valid_accs.append(evaluate(model, X_test))
print('Valid acc: %.4f' % (valid_accs[-1]))
# display the epoch training loss
return losses
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
totensor = lambda x : torch.from_numpy(x).to(device)#.float().to(device) #.astype('float')
#Split into trainning and testing data
X_train, X_test, y_train, y_test = train_test_split(
X, y, stratify=y, random_state=0, test_size=0.33
)
model = Autoencoder(
latent_size=3,
encoder_dims=[500,250],
decoder_dims=[250,500],
input_size=X_train.shape[1],
activation=ComplexReLU()#nn.Identity()
)
print(model)
losses = train(
model=model,
X_train_noisy=X_train,
X_test=X_test,
epochs=100,
lr=4e-3
)