Sir This is my model
I want to fix some filters to zero and don’t want them to update when the model learns
so I want to make their gradients as zero as well
class my_model(nn.Module):
def __init__(self):
super(my_model,self).__init__()
self.conv1 = nn.Conv2d(3,16,kernel_size=3,stride=1,padding=1)
self.conv2 = nn.Conv2d(16,32,kernel_size=3,stride=1,padding=1)
self.conv3 = nn.Conv2d(32,64,kernel_size=3,stride=1,padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(4*4*64,64)
self.fc2 = nn.Linear(64,10)
def forward(self,inp):
ab = self.pool(F.relu(self.conv1(inp)))
ab = self.pool(F.relu(self.conv2(ab)))
ab = self.pool(F.relu(self.conv3(ab)))
ab = ab.view(ab.shape[0],-1)
ab = F.relu(self.fc1(ab))
ab = F.relu(self.fc2(ab))
return ab
> I loaded the model from a previous checkpoint
new_test_model = my_model()
a = torch.load("/content/cifar_net.pth")
new_test_model.load_state_dict(a)
new_test_model.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(new_test_model.parameters(), lr=0.001)
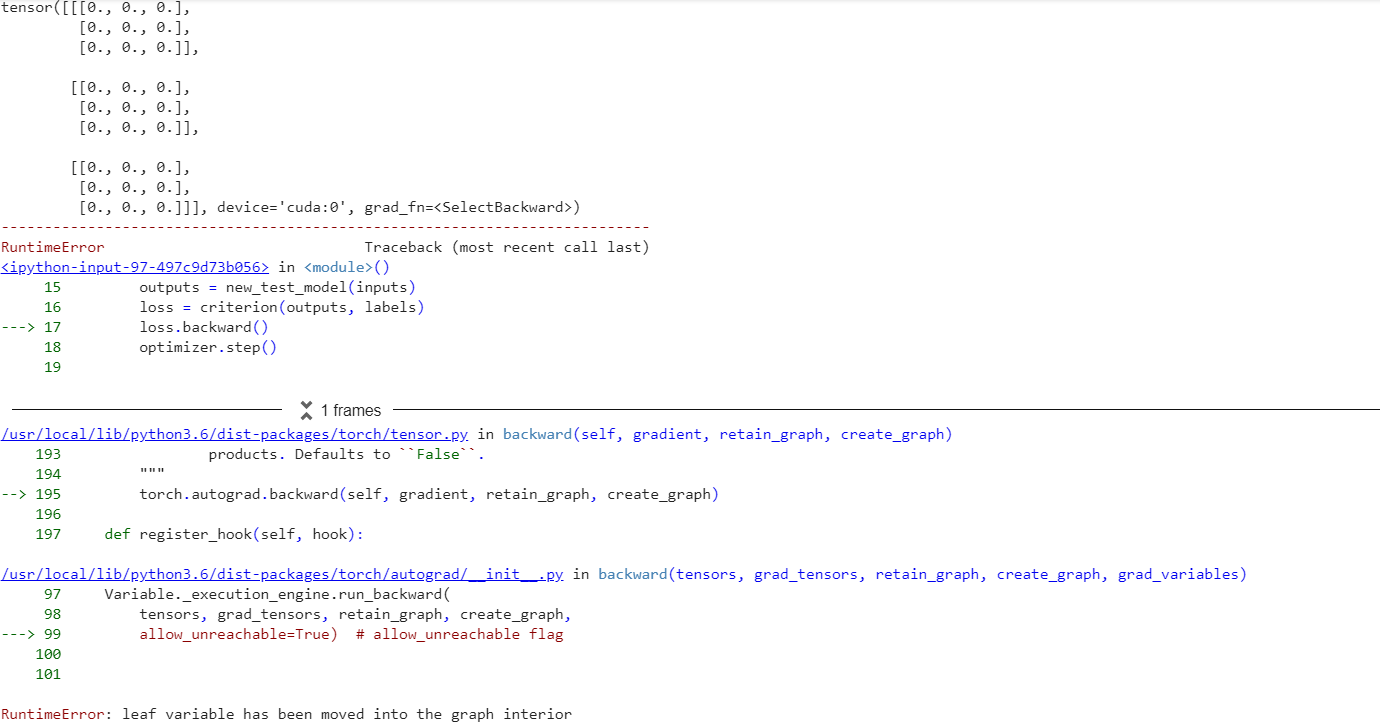
> I executed once to check if the model was updating weights or not
optimizer.zero_grad()
inputs, labels = iter(trainloader).next()
inputs, labels = inputs.cuda(), labels.cuda()
outputs = new_test_model(inputs)
loss = criterion(outputs, labels)
print("before loss backward")
loss.backward()
print("after loss backward")
optimizer.step()
print("after opt step")
> I want to make the weights of these layers as zero according to the dictionary below
indices = {
'conv1':[0,3,9,5,7,2],
'conv2':[10,13,19,25,17,22],
'conv3':[20,31,29,15,27,12],
}
As you suggested I used this code to make the filters zero
# code to make the filters zero
for index, item in enumerate(new_test_model.named_children()):
with torch.no_grad():
if(isinstance(item[1],nn.Conv2d)):
wt_list = indices[item[0]]
for i in wt_list:
item[1].weight[i].copy_(torch.zeros_like(item[1].weight[i]))
item[1].bias[i].copy_(torch.zeros_like(item[1].bias[i]))
Then I checked the weights, they were zero, as I wanted them to be
# code to check the filters if they turned to zero
for index, item in enumerate(new_test_model.named_children()):
with torch.no_grad():
if(isinstance(item[1],nn.Conv2d)):
wt_list = indices[item[0]]
for i in wt_list:
print(item[1].weight[i])
Then I executed the code below to make the gradients again
optimizer.zero_grad()
inputs, labels = iter(trainloader).next()
inputs, labels = inputs.cuda(), labels.cuda()
outputs = new_test_model(inputs)
loss = criterion(outputs, labels)
loss.backward()
And then I checked the gradients
for index, item in enumerate(new_test_model.named_children()):
if(isinstance(item[1],nn.Conv2d)):
wt_list = indices[item[0]]
for i in wt_list:
print(item[1].weight.grad[i,:,:,:])
They turned out to be non zero as expected
because till now I have not made them as zero
Then I turned the gradients to be zero using the code below
print("after loss backward")
for index, item in enumerate(new_test_model.named_children()):
if(isinstance(item[1],nn.Conv2d)):
wt_list = indices[item[0]]
for i in wt_list:
item[1].weight.grad[i,:,:,:]=0
item[1].bias.grad[i]=0
And checked the gradients again and they were zero as expected
so when the gradients were Zero and the filters were themselves Zero there should be NO update in the filters but the filters were updated
The filters from being zero despite the gradients being zero got updated to non zero.
and to add to this even after I did optimizer.zero_grad()
without calculating the loss again and executing loss.backward()
just to check that even when all gradients are zero if then also the model is updated,
then also using just optimizer.zero_grad() and then optimizer.step()
the model got updated again.
Can you please explain what is happening or what am i missing or doing wrong.
I just want to make the filters zero and don’t want them to update