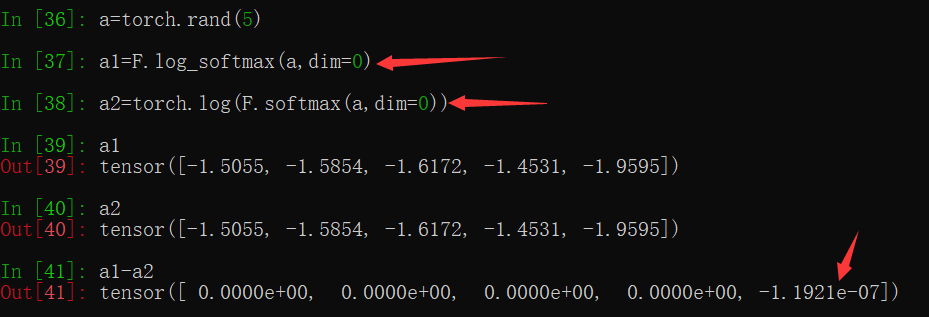
it might have to do with logsumexp trick applied in F.log_softmax,
I carried following experiment,
import torch.nn as nn, torch, torch.nn.functional as F
from math import exp, log
torch.set_printoptions(precision=15)
x = torch.randn(5); x
tensor([ 2.229876756668091, 0.264560282230377, -0.100190632045269,
0.228291451931000, -0.119905993342400])
a = torch.softmax(x, dim=0); a
tensor([0.681239962577820, 0.095449574291706, 0.066277280449867,
0.092049762606621, 0.064983405172825])
torch.log(a)
tensor([-0.383840680122375, -2.349157094955444, -2.713908195495605,
-2.385426044464111, -2.733623266220093])
while
F.log_softmax(x, dim=0)
gives
tensor([-0.383840620517731, -2.349157094955444, -2.713907957077026,
-2.385425806045532, -2.733623266220093])
we see a difference in values obtained,
torch.log(a) - F.log_softmax(x, dim=0)
tensor([-5.960464477539062e-08, 0.000000000000000e+00, -2.384185791015625e-07,
-2.384185791015625e-07, 0.000000000000000e+00])
the first case (for 3rd value) is equivalent to,
log(exp(x[2])/(exp(x[0]) + exp(x[1]) + exp(x[2]) + exp(x[3]) + exp(x[4])))
-2.7139080429149542
while the second case is equivalent to,
x[2] - x[0] - log((exp(0) + exp(x[1] - x[0]) + exp(x[2] - x[0]) + exp(x[3] - x[0]) + exp(x[4] - x[0])))
-2.713907957077026
I think it done to avoid exponential of a large number