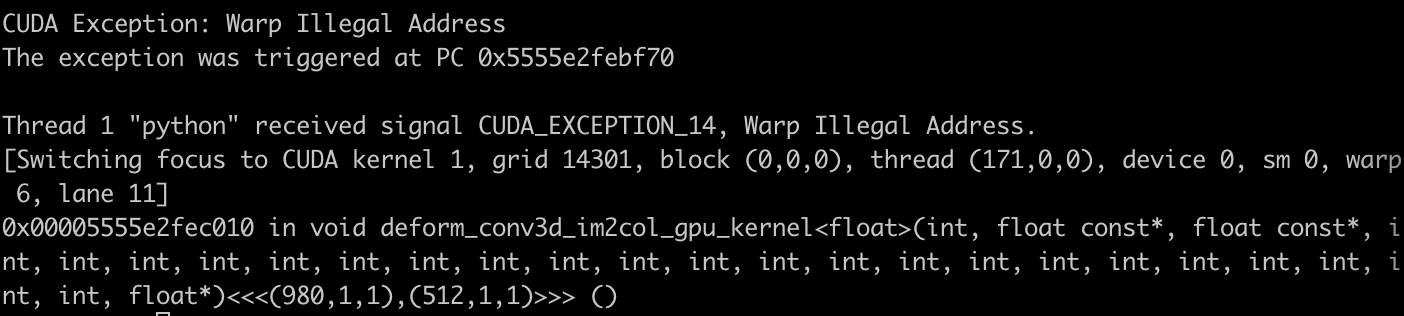
Hello. I’m modifying a CUDA code of deformable convolution to work with circular padding, and the main change is to introduce modulo operation on the translated coordinates by offsets. I tried two versions that do the same thing, but the problem is that one raises an error, but the other works well. I want to ask you the difference or the reason for the error as I think they are the same in functions.
The base code I used is GitHub - CHONSPQX/modulated-deform-conv: deformable convolution 2D 3D DeformableConvolution DeformConv Modulated Pytorch CUDA. You can test the code by simply replacing the trilinear interpolation part in src/deformable_conv3d.cu.
The central part that I changed is the lines 25-27, which involve modulo operation.
Line 27 does not raise an error, and I think this covers the discrepancy between version 1 and version 2.
7 template
8 device scalar_t deform_conv3d_im2col_trilinear(
9 const scalar_t *bottom_data, const int data_width,const int data_length,
10 const int height, const int width, const int length,scalar_t h, scalar_t w,scalar_t l)
11 {
12
13 int h_low = floor(h);
14 int w_low = floor(w);
15 int l_low = floor(l);
17 int w_high = w_low + 1;
18 int l_high = l_low + 1;
19
20 scalar_t lh = h - h_low;//dh
21 scalar_t lw = w - w_low;//dw
22 scalar_t ll = l - l_low;//dl
23 scalar_t hh = 1 - lh, hw = 1 - lw, hl = 1 - ll; //1-dh 1-dw 1-dl
24
25 h_low = ((h_low % height) + height) % height;
26 h_high = ((h_high % height) + height) % height;
27 assert(h_low >= 0 && h_high <= height - 1);
The code of 28-49 lines is the version1 that raises an error of CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling cublasCreate(handle)
28 /*
29 scalar_t v1 = 0;
30 scalar_t v5 = 0;
31 if (w_low >= 0 && l_low >= 0)
32 v1 = bottom_data[h_low * data_widthdata_length + w_lowdata_length+ l_low];
33 v5 = bottom_data[h_high * data_widthdata_length + w_lowdata_length+ l_low];
34 scalar_t v2 = 0;
35 scalar_t v6 = 0;
36 if (w_low >=0 && l_high<= length -1)
37 v2 = bottom_data[h_low * data_widthdata_length + w_lowdata_length+ l_high];
38 v6 = bottom_data[h_high * data_widthdata_length + w_lowdata_length+ l_high];
39 scalar_t v3 = 0;
40 scalar_t v7 = 0;
41 if (w_high <= width - 1 && l_low >= 0)
42 v3 = bottom_data[h_low * data_widthdata_length + w_highdata_length+ l_low];
43 v7 = bottom_data[h_high * data_widthdata_length + w_highdata_length+ l_low];
44 scalar_t v4 = 0;
45 scalar_t v8 = 0;
46 if (w_high <= width - 1 && l_high<= length -1)
47 v4 = bottom_data[h_low * data_widthdata_length + w_highdata_length+ l_high];
48 v8 = bottom_data[h_high * data_widthdata_length + w_highdata_length+ l_high];
49 */
The code of 50-76 lines is version2 which works without error.
50 /*
51 scalar_t v1 = 0;
52 if (h_low >= 0 && w_low >= 0 && l_low >= 0)
53 v1 = bottom_data[h_low * data_widthdata_length + w_lowdata_length+ l_low];
54 scalar_t v2 = 0;
55 if (h_low >= 0 && w_low >=0 && l_high<= length -1)
56 v2 = bottom_data[h_low * data_widthdata_length + w_lowdata_length+ l_high];
57 scalar_t v3 = 0;
58 if (h_low >= 0 && w_high <= width - 1 && l_low >= 0)
59 v3 = bottom_data[h_low * data_widthdata_length + w_highdata_length+ l_low];
60 scalar_t v4 = 0;
61 if (h_low >= 0 && w_high <= width - 1 && l_high<= length -1)
62 v4 = bottom_data[h_low * data_widthdata_length + w_highdata_length+ l_high];
63
64 scalar_t v5 = 0;
65 if (h_high <= height -1 && w_low >= 0 && l_low >= 0)
66 v5 = bottom_data[h_high * data_widthdata_length + w_lowdata_length+ l_low];
67 scalar_t v6 = 0;
68 if (h_high <= height -1 && w_low >= 0 && l_high<= length -1)
69 v6 = bottom_data[h_high * data_widthdata_length + w_lowdata_length+ l_high];
70 scalar_t v7 = 0;
71 if (h_high <= height -1 && w_high <= width - 1 && l_low >= 0)
72 v7 = bottom_data[h_high * data_widthdata_length + w_highdata_length+ l_low];
73 scalar_t v8 = 0;
74 if (h_high <= height -1 && w_high <= width - 1 && l_high<= length -1)
75 v8 = bottom_data[h_high * data_widthdata_length + w_highdata_length+ l_high];
76 */
The rest part performs the interpolation.
77 scalar_t w1 = hh * hw *hl, w2 = hh hw ll, w3 = hh * lwhl, w4 = hh * lw ll;
78 scalar_t w5 = lh * hw *hl, w6 = lh hw ll, w7 = lh * lwhl, w8 = lh * lw ll;
79
80 scalar_t val = (w1 * v1 + w2 * v2 + w3 * v3 + w4 * v4+w5 * v5 + w6 * v6 + w7 * v7 + w8 * v8);
81 return val;
82 }
Any comment or help on this would be appreciated!