I am trying to build network with a new structure,The model is built with two separated class.When I run it,the error says that :optimizer got an empty parameter list.I am new to PyTorch and I don’t know what causes the error.Can you give me some suggestions?Thank you!
6 Likes
This happens because model.parameters() is empty.
It might probably happen because all your parameters are inside a list which is attributed to the model, and pytorch can’t find them. Something like
self.myparameters = [Parameter1, Parameter2, ...]
If that is the case, then you should use nn.ParameterList instead.
self.myparameters = nn.ParameterList(Parameter1, Parameter2, ...)
14 Likes
Yes it works now!
Thank you very much
Hi. I am also facing a similar kind of scenario. I am trying to implement a simple GAN with generator and discriminator being respective classes.
# Generator Neural Network Model (1 hidden layer)
class GNet(nn.Module):
def __init__(self, input_size, hidden_size, image_size):
super(GNet, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, image_size),
)
def forward(self, x):
return self.model(x)
# Discriminator Neural Network Model (2 hidden layer)
class DNet(nn.Module):
def __init__(self, image_size, hidden_size):
super(DNet, self).__init__()
self.model = nn.Sequential(
nn.Linear(image_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, num_classes),
)
def forward(self, x):
return self.model(x)
G = GNet(input_size, hidden_size, image_size)
D = DNet(image_size, hidden_size)
G_params = G.parameters()
D_params = D.parameters()
G_solver = optim.Adam(G_params, lr=1e-3)
D_solver = optim.Adam(D_params, lr=1e-3)
I am getting the error message in the line of G_solver:
ValueError: optimizer got an empty parameter list
Why I am I not getting the parameter list even if I am calling D.parameters()
Do:
G_params = list(G.parameters())
D_params = list(D.parameters())
.parameters() is a generator, and probably for debugging purposes you are pre-populating it somewhere.
3 Likes
class Netz ( nn.Module ):
def _init_(self):
super ( Netz, self ).__init__ ()
self.conv1 = nn.Conv2d ( 1, 10, kernel_size=5 )
self.conv2 = nn.Conv2d ( 10, 20, kernel_size=5 )
self.conv_dropout = nn.Dropout2d ()
self.fc1 = nn.Linear ( 320, 60 )
self.fc2 = nn.Linear ( 60, 10 )
def forward(self, x):
x = self.conv1 ( x )
x = F.max_pool2D ( x, 2 )
x = F.relu ( x )
x = self.conv2 ( x )
x = self.conv_dropout ( x )
x = F.max_pool2D ( x, 2 )
x = F.relu ( x )
x = x.view ( -1, 320 )
x = F.relu ( self.fc1 ( x ) )
x = self.fc2 ( x )
return F.log_softmax ( x )
model = Netz()
model.cuda()
optimizer = optim.SGD( model.parameters (), lr=0.1, momentum=0.8 )
def train(epoch):
model.train ()
for batch_id, (data, target) in enumerate ( train_data ):
data = data.cuda ()
target = target.cuda ()
data = Variable ( data )
target: Variable = Variable ( target )
optimizer.zero_grad ()
out = model ( data )
criterion = F.nll_loss
loss = criterion ( out, target )
loss.backward ()
optimizer.step ()
print ( 'Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format ( epoch, batch_id * len ( data ),
len ( train_data.dataset ),
100. * batch_id / len ( train_data ),
loss.data[0] ) )
for epoch in range ( 1, 30 ):
train ( epoch )
the same Error here:
ValueError: optimizer got an empty parameter list --> optimizer = optim.SGD( model.parameters (), lr=0.1, momentum=0.8 )
I have change to: optimizer = optim.SGD(list( model.parameters ()), lr=0.1, momentum=0.8 ) -> also the same Error
Where is the failure?
OK, done! i got the failure!
My def init(self): was incorrect typed
3 Likes
I am having the same issue with a different architecture. Specifically, I am trying to build a stacked LSTM, where each layer may have a different number of units. It would be very convenient to pass a list of layer sizes as an argument and have the same function build the network as appropriate. Every attempt has failed:
-
The most obvious way is to build lists of ‘torch.nn.LSTM’ and hidden layers, and manage them directly. This fails, I think, because they are “hidden” in a list, even though defined in the init routine.
-
Similarly, but for completeness, building a dict of layers with integer keys failed, for what I believe is the same reason.
-
A rather horrible attempt to use ‘vars(self)’ to force-construct meaningful variable names failed in a more complicated way, and honestly, it’s a terrible idea anyway.
What is the accepted way to do what I’m trying to do, without re-implementing the whole LSTM architecture myself? Is there a way to force the registration of the LSTM objects with the parameters list?
I made the same error with you, so embarrassed…
Hi,
I am newer, I tried to make myown operation with PyTorch, then I meet this error.
So, I try to code as follows;
self.myparameters = nn.ParameterList(self.w, self.out_w1, self.out_b1, self.out_w2, self.out_b2)
This is in init(self) and all parameters are like this;
self.w = torch.randn((NUM_INPUT, NUM_HIDDEN), requires_grad=True)
Error Message is as follows;
TypeError Traceback (most recent call last)
<ipython-input-75-31d214f55eb8> in <module>()
33 return out2
34
---> 35 model = Model().to(device)
36 optimizer = optim.SGD(model.parameters(), lr=lr)
37 criterion = nn.CrossEntropyLoss()
<ipython-input-75-31d214f55eb8> in __init__(self)
24 self.out_b2= torch .randn((NUM_CLASSES), requires_grad=True)
25
---> 26 self.myparameters = nn.ParameterList(self.w, self.out_w1, self.out_b1, self.out_w2, self.out_b2)
27
28 def forward(self, x):
TypeError: __init__() takes from 1 to 2 positional arguments but 6 were given
What does the message mean? and how to solve?
Not sure what you are trying to do, but the error is because nn.ParameterList takes an iterable as input, see https://pytorch.org/docs/stable/nn.html#torch.nn.ParameterList, try
self.myparameters = nn.ParameterList([self.w, self.out_w1, self.out_b1, self.out_w2, self.out_b2])
Sure, I did.
My model is;
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
# Gate-Weight
self.w = torch.randn((NUM_INPUT, NUM_HIDDEN), requires_grad=True)
# Gate-Selector
self.sel = torch.zeros(NUM_INPUT, NUM_HIDDEN)
# Input Vector
self.fw_x = torch.zeros(NUM_INPUT, NUM_HIDDEN)
# Output Vector
self.fw_h = torch.zeros(NUM_INPUT, NUM_HIDDEN)
# Output Layer
self.out_w1= torch.randn((NUM_HIDDEN), requires_grad=True)
self.out_b1= torch.randn((NUM_INPUT), requires_grad=True)
self.out_w2= torch.randn((NUM_CLASSES, NUM_INPUT), requires_grad=True)
self.out_b2= torch.randn((NUM_CLASSES), requires_grad=True)
#self.myparameters = nn.ParameterList([self.w, self.out_w1, self.out_b1, self.out_w2, self.out_b2])
def forward(self, x):
fw_prop(self, x)
out1 = torch.matmul(self.fw_h, self.out_w1) + self.out_b1
out2 = torch.matmul(self.out_w2, out1) + self.out_b2
return out2
model = Model().to(device)
optimizer = optim.SGD(model.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
Then;
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-12-c94710f76e27> in <module>()
36 model = Model().to(device)
37 #model.myparameters = torch.nn.Parameter(model.w, model.out_w1, model.out_b1, model.out_w2, model.out_b2)
---> 38 optimizer = optim.SGD(model.parameters(), lr=lr)
39 criterion = nn.CrossEntropyLoss()
1 frames
/usr/local/lib/python3.6/dist-packages/torch/optim/optimizer.py in __init__(self, params, defaults)
43 param_groups = list(params)
44 if len(param_groups) == 0:
---> 45 raise ValueError("optimizer got an empty parameter list")
46 if not isinstance(param_groups[0], dict):
47 param_groups = [{'params': param_groups}]
ValueError: optimizer got an empty parameter list
So I did both of
ParameterList(...)
and
ParameterList([...])
Last one has error of;
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-13-87872cf3c699> in <module>()
34 return out2
35
---> 36 model = Model().to(device)
37 optimizer = optim.SGD(model.parameters(), lr=lr)
38 criterion = nn.CrossEntropyLoss()
4 frames
<ipython-input-13-87872cf3c699> in __init__(self)
25 self.out_b2= torch.randn((NUM_CLASSES), requires_grad=True)
26
---> 27 self.myparameters = nn.ParameterList([self.w, self.out_w1, self.out_b1, self.out_w2, self.out_b2])
28
29 def forward(self, x):
/usr/local/lib/python3.6/dist-packages/torch/nn/modules/container.py in __init__(self, parameters)
360 super(ParameterList, self).__init__()
361 if parameters is not None:
--> 362 self += parameters
363
364 def _get_abs_string_index(self, idx):
/usr/local/lib/python3.6/dist-packages/torch/nn/modules/container.py in __iadd__(self, parameters)
389
390 def __iadd__(self, parameters):
--> 391 return self.extend(parameters)
392
393 def __dir__(self):
/usr/local/lib/python3.6/dist-packages/torch/nn/modules/container.py in extend(self, parameters)
416 offset = len(self)
417 for i, param in enumerate(parameters):
--> 418 self.register_parameter(str(offset + i), param)
419 return self
420
/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py in register_parameter(self, name, param)
155 raise TypeError("cannot assign '{}' object to parameter '{}' "
156 "(torch.nn.Parameter or None required)"
--> 157 .format(torch.typename(param), name))
158 elif param.grad_fn:
159 raise ValueError(
TypeError: cannot assign 'torch.FloatTensor' object to parameter '0' (torch.nn.Parameter or None required)
The iterative means of;
417 for i, param in enumerate(parameters):
--> 418 self.register_parameter(str(offset + i), param)
Is my understanding a correct?
self.fc1 = nn.Linear(NUM_HIDDEN, 1)
self.fc2 = nn.Linear(NUM_INPUT, NUM_CLASSES)
with transpose, then no error, so probably error is on a shape.
You can do this instead optimizer = optim.SGD( params = model.parameters (), lr=0.1, momentum=0.8 )
You should do this G_solver = optim.Adam(params = G_params, lr=1e-3)
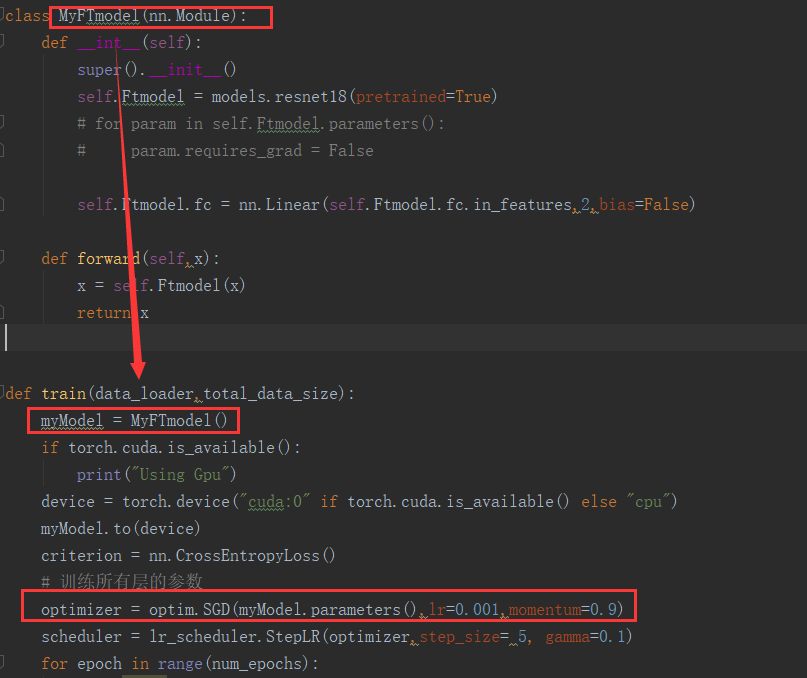
Fix the typo in def __init__ (missing i) and it should work.
1 Like
Same issue, was using __init_ instead of __init__
very hard to see lol
I got this error because I failed to properly use self. in the __init__ of my nn.Module class.
For example, I used layer1 = nn.Linear(input_size,hidden_size)
instead of self.layer1 = nn.Linear(input_size,hidden_size).
Easy mistake to make, but it took me a while to figure out
Hello I am also facing the same issue. Can anyone please help me.
from turtle import forward
import torch
import torch.nn as nn
class NeuralNet(nn.Module):
def init(self, input_size, hidden_size, num_classes):
super(NeuralNet, self).init()
self.l1 = nn.AdaptiveMaxPool2d(input_size, hidden_size)
self.l2 = nn.AdaptiveMaxPool2d(hidden_size, hidden_size)
self.l1 = nn.AdaptiveMaxPool2d(hidden_size, num_classes)
self.relu = nn.ReLU()
def forward(self, x):
out = self.l1(x)
out = self.relu(out)
out = self.l2(out)
out = self.relu(out)
out = self.l3(out)
#no activation and no softmax
return out
[nltk_data] Downloading package punkt to
[nltk_data] C:\Users\Hp\AppData\Roaming\nltk_data…
[nltk_data] Package punkt is already up-to-date!
Traceback (most recent call last):
File “c:/Users/Hp/Desktop/rafay pytorch/train.py”, line 77, in
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
File “C:\Users\Hp\AppData\Local\Programs\Python\Python38\lib\site-packages\torch\optim\adam.py”, line 90, in init
super(Adam, self).init(params, defaults)
File “C:\Users\Hp\AppData\Local\Programs\Python\Python38\lib\site-packages\torch\optim\optimizer.py”, line 49, in
init
raise ValueError(“optimizer got an empty parameter list”)
ValueError: optimizer got an empty parameter list