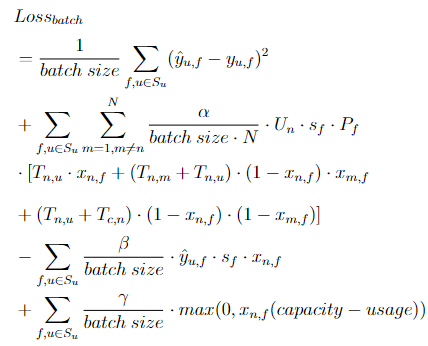I’m trying to make my own batch loss function like below
class CustomLoss(torch.nn.Module):
def __init__(self):
super(CustomLoss, self).__init__()
def forward(self, input, target, x_hat, U, sf, Tnu, Tnm, Tcn, x1, x2, acc_prob):
diff = input - target
all_pairs = torch.cat((x1, x2), dim=1)
sf_tensor = torch.tensor(sf)
acc_prob_tensor = torch.tensor(acc_prob)
num_data = len(all_pairs)
n = k
item_list = all_pairs[:, 1]
valid_indices = torch.arange(num_local)[torch.arange(num_local) != n]
loss = 0
global x_init
x = x_init.clone()
with torch.no_grad():
x[n, item_list] = x_hat.squeeze()
x_init[n, item_list] = x[n, item_list]
with torch.no_grad():
usage = torch.sum(x[n] * sf_tensor)
term3 = 0.0001 * d * (-torch.sum(input * sf_tensor[item_list] * torch.log(x_hat)) / num_data)
term4 = 0.00000001 * a * (-torch.sum(torch.pow(torch.maximum(torch.tensor(0), x_hat * capacity_limit - x_hat * usage), 2)) / num_data)
x_valid = x[valid_indices][: , item_list]
u = all_pairs[:, 0]
f = all_pairs[:, 1]
term1 = 0
for m in range(num_local):
if m != n:
term1 = term1 + U[n] * sf_tensor[f] * acc_prob_tensor[f] * (Tnu[n, u] * x[n, item_list] + \
(Tnm[n, valid_indices].unsqueeze(1) + Tnu[n, u]).unsqueeze(1) * \
(1 - x[n, f]) * x[m, f] + (Tnu[n, u] + Tcn[n]) * (1 - x[n, f]) * \
(1 - x[m, f]))
loss = b * (torch.sum(term1) / (num_data * (num_local - 1)))
k_loss2.append(term3.item())
k_loss3.append(term4.item())
loss = loss + term3
loss = loss + torch.mean(torch.pow(diff, 2))
k_loss123.append(loss.item())
return loss
n just an integer, x_init is a tensor that I want to update by x_hat
input and x_hat is my model’s output
I use relu activation function to get input and softmax function to get x_hat in my network model
it can work for two rounds, but in the third round, I got the error image when doing the backwards
RuntimeError: Function 'SoftmaxBackward0' returned nan values in its 0th output.
and here is the loss function I’m trying to implement