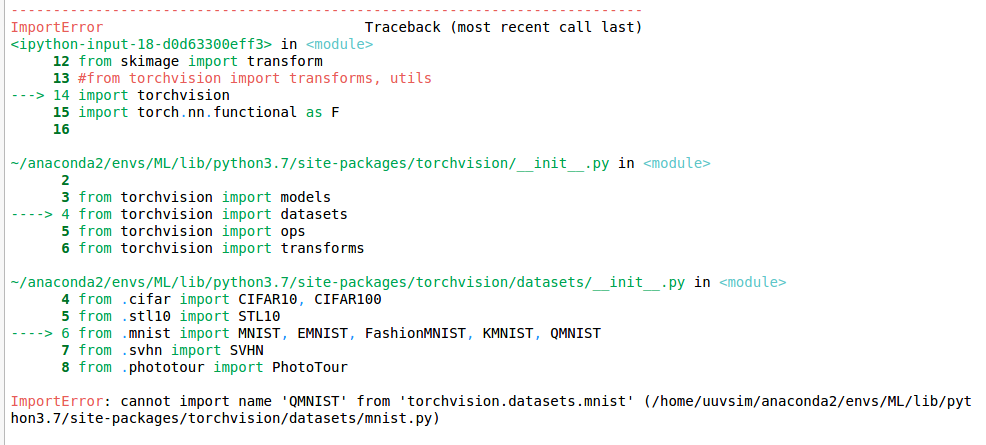
They are:
MNIST, FashionMNIST, KMNIST, EMNIST, QMNIST.
I copied QMNIST :
class QMNIST(MNIST):
“”"QMNIST <https://github.com/facebookresearch/qmnist>_ Dataset.
Args:
root (string): Root directory of dataset whose ``processed''
subdir contains torch binary files with the datasets.
what (string,optional): Can be 'train', 'test', 'test10k',
'test50k', or 'nist' for respectively the mnist compatible
training set, the 60k qmnist testing set, the 10k qmnist
examples that match the mnist testing set, the 50k
remaining qmnist testing examples, or all the nist
digits. The default is to select 'train' or 'test'
according to the compatibility argument 'train'.
compat (bool,optional): A boolean that says whether the target
for each example is class number (for compatibility with
the MNIST dataloader) or a torch vector containing the
full qmnist information. Default=True.
download (bool, optional): If true, downloads the dataset from
the internet and puts it in root directory. If dataset is
already downloaded, it is not downloaded again.
transform (callable, optional): A function/transform that
takes in an PIL image and returns a transformed
version. E.g, ``transforms.RandomCrop``
target_transform (callable, optional): A function/transform
that takes in the target and transforms it.
train (bool,optional,compatibility): When argument 'what' is
not specified, this boolean decides whether to load the
training set ot the testing set. Default: True.
"""
subsets = {
'train': 'train',
'test': 'test',
'test10k': 'test',
'test50k': 'test',
'nist': 'nist'
}
resources = {
'train': [('https://raw.githubusercontent.com/facebookresearch/qmnist/master/qmnist-train-images-idx3-ubyte.gz',
'ed72d4157d28c017586c42bc6afe6370'),
('https://raw.githubusercontent.com/facebookresearch/qmnist/master/qmnist-train-labels-idx2-int.gz',
'0058f8dd561b90ffdd0f734c6a30e5e4')],
'test': [('https://raw.githubusercontent.com/facebookresearch/qmnist/master/qmnist-test-images-idx3-ubyte.gz',
'1394631089c404de565df7b7aeaf9412'),
('https://raw.githubusercontent.com/facebookresearch/qmnist/master/qmnist-test-labels-idx2-int.gz',
'5b5b05890a5e13444e108efe57b788aa')],
'nist': [('https://raw.githubusercontent.com/facebookresearch/qmnist/master/xnist-images-idx3-ubyte.xz',
'7f124b3b8ab81486c9d8c2749c17f834'),
('https://raw.githubusercontent.com/facebookresearch/qmnist/master/xnist-labels-idx2-int.xz',
'5ed0e788978e45d4a8bd4b7caec3d79d')]
}
classes = ['0 - zero', '1 - one', '2 - two', '3 - three', '4 - four',
'5 - five', '6 - six', '7 - seven', '8 - eight', '9 - nine']
def __init__(self, root, what=None, compat=True, train=True, **kwargs):
if what is None:
what = 'train' if train else 'test'
self.what = verify_str_arg(what, "what", tuple(self.subsets.keys()))
self.compat = compat
self.data_file = what + '.pt'
self.training_file = self.data_file
self.test_file = self.data_file
super(QMNIST, self).__init__(root, train, **kwargs)
def download(self):
"""Download the QMNIST data if it doesn't exist in processed_folder already.
Note that we only download what has been asked for (argument 'what').
"""
if self._check_exists():
return
makedir_exist_ok(self.raw_folder)
makedir_exist_ok(self.processed_folder)
split = self.resources[self.subsets[self.what]]
files = []
# download data files if not already there
for url, md5 in split:
filename = url.rpartition('/')[2]
file_path = os.path.join(self.raw_folder, filename)
if not os.path.isfile(file_path):
download_url(url, root=self.raw_folder, filename=filename, md5=md5)
files.append(file_path)
# process and save as torch files
print('Processing...')
data = read_sn3_pascalvincent_tensor(files[0])
assert(data.dtype == torch.uint8)
assert(data.ndimension() == 3)
targets = read_sn3_pascalvincent_tensor(files[1]).long()
assert(targets.ndimension() == 2)
if self.what == 'test10k':
data = data[0:10000, :, :].clone()
targets = targets[0:10000, :].clone()
if self.what == 'test50k':
data = data[10000:, :, :].clone()
targets = targets[10000:, :].clone()
with open(os.path.join(self.processed_folder, self.data_file), 'wb') as f:
torch.save((data, targets), f)
def __getitem__(self, index):
# redefined to handle the compat flag
img, target = self.data[index], self.targets[index]
img = Image.fromarray(img.numpy(), mode='L')
if self.transform is not None:
img = self.transform(img)
if self.compat:
target = int(target[0])
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
def extra_repr(self):
return "Split: {}".format(self.what)