I trained a LSTM model on my gpu device which can work well on both training and testing phases.
Following is my corresponding code.
class LSTM(nn.Module):
def __init__(self, feature_dim, hidden_dim, tagset_size):
super(LSTM, self).__init__()
self.hidden_dim = hidden_dim
self.lstm = nn.LSTM(feature_dim, hidden_dim)
self.hidden2tag = nn.Linear(hidden_dim, tagset_size)
self.hidden = self.init_hidden()
def init_hidden(self):
return (autograd.Variable(torch.zeros(1,1,self.hidden_dim).cuda()),
autograd.Variable(torch.zeros(1,1,self.hidden_dim).cuda()))
def forward(self, vec_seq):
vec_seq = autograd.Variable(vec_seq)
lstm_out, self.hidden = self.lstm(
vec_seq.view(len(vec_seq),1,-1), self.hidden)
tag_space = self.hidden2tag(lstm_out.view(len(vec_seq),-1))
tag_scores = F.log_softmax(tag_space)
return tag_scores
To make it work on cuda, I added following codes.
model = LSTM(FEATURE_DIM, HIDDEN_DIM, len(tags)).cuda()
loss_function = nn.NLLLoss().cuda()
Every epoch I trained, I also transformed my data into cuda type.
ts = torch.Tensor(training_data[i]).float().cuda()
tt = autograd.Variable(torch.Tensor([training_targets[i]]).view(1).cuda())
The codes above run well on my GPU. However, when I want to run the testing phase on CPU, some errors occur.
Following is my code:
model.cpu()
for i in range(len(test_data)):
ts = torch.FloatTensor(test_data[i])
tt = autograd.Variable(torch.FloatTensor([test_targets[i]]).view(1))
tag_scores = model(ts)
last_output = tag_scores[-1].view(1,-1)
pred_y = torch.max(last_output,1)[1].data.numpy()
print 'id = ', tt, 'pred_y = ', pred_y
if test_targets[i] == pred_y[0]:
prec += 1
nsamp += 1
print 'precision = ', prec*1.0/nsamp
I have printed the model.state_dict(), the outputs are all torch.FloatTensor of size 64. Therefore it seems the model has been transferred to CPU side?
The error messages are like the attached image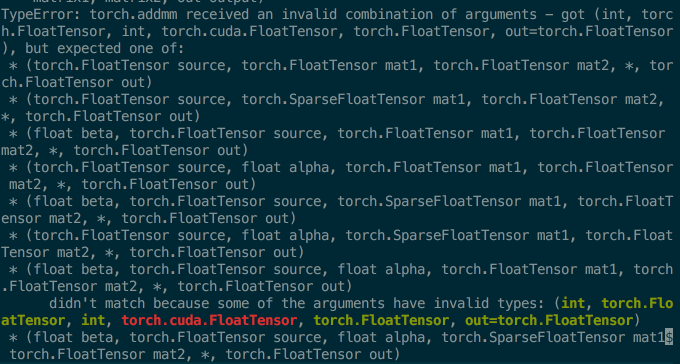
I also tried the way of save()->load() like the following code shows.
torch.save(model.state_dict(), 'model_2_cuda.pt')
torch.load('model_2_cuda.pt', map_location=lambda storage, loc: storage)
But it still does not work.
I have checked my code and did not find anything with type torch.cuda.FloatTensor.
Could anyone help me with some tips?
Thanks.