I did some search and came up with some solution and applied it in my code but still I am having some confusions and also getting errors. So, I am posting my changed code over here:
Question : If I am not passing saved optimizer in my fit function then how it is calculating accuracy and loss?
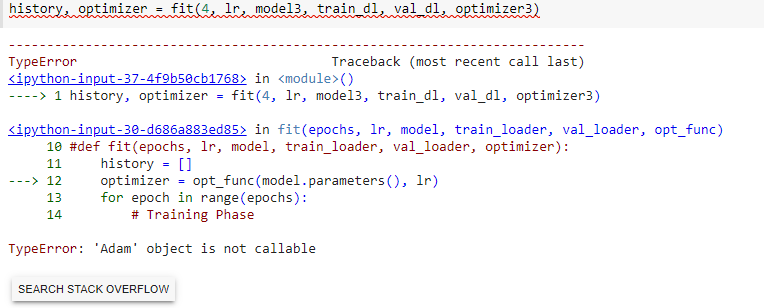
Confusion: When I am passing optimizer3(saved optimizer) in fit function it is throwing error “Adam is not callable”. (For reference please check attached snapshot).Kindly help me understand the cause of this issue and provide the way to resolve it.
Model Training
@torch.no_grad()
def evaluate(model, val_loader):
model.eval()
outputs = [model.validation_step(batch) for batch in val_loader]
return model.validation_epoch_end(outputs)
#optimizer = torch.optim.Adam(model.parameters(), lr)
def fit(epochs, lr, model, train_loader, val_loader, opt_func=torch.optim.SGD):
#def fit(epochs, lr, model, train_loader, val_loader, optimizer):
history = []
optimizer = opt_func(model.parameters(), lr)
for epoch in range(epochs):
# Training Phase
model.train()
train_losses = []
for batch in train_loader:
loss = model.training_step(batch)
train_losses.append(loss)
loss.backward()
optimizer.step()
optimizer.zero_grad()
# Validation phase
result = evaluate(model, val_loader)
result['train_loss'] = torch.stack(train_losses).mean().item()
model.epoch_end(epoch, result)
history.append(result)
return history, optimizer
num_epochs = 2
opt_func = torch.optim.Adam
lr = 0.001
history, optimizer = fit(num_epochs, lr, model, train_dl, val_dl, opt_func)
Output:
Epoch [0], train_loss: 1.7836, val_loss: 1.4373, val_acc: 0.4659
Epoch [1], train_loss: 1.2700, val_loss: 1.1127, val_acc: 0.6018
# Saving the model and optimizer
torch.save({
'epoch': num_epochs,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict()
}, 'CNN-model.pt')
# Load the model and optimizer
model3 = to_device(Cifar10CnnModel(), device) # instantiate model
optimizer3 = torch.optim.Adam(model3.parameters(), lr) # instantiate optimizer
checkpoint = torch.load('CNN-model.pt')
model3.load_state_dict(checkpoint['model_state_dict']) # Load model
optimizer3.load_state_dict(checkpoint['optimizer_state_dict']) # load optimizer
epoch = checkpoint['epoch']
history, optimizer = fit(4, lr, model3, train_dl, val_dl) # no optimizer
Output:
Epoch [0], train_loss: 1.0236, val_loss: 1.0559, val_acc: 0.6151
Epoch [1], train_loss: 1.0089, val_loss: 1.0491, val_acc: 0.6178
Epoch [2], train_loss: 1.0020, val_loss: 1.0447, val_acc: 0.6209
Epoch [3], train_loss: 0.9967, val_loss: 1.0421, val_acc: 0.6193