I plan to use the base layers of pre-trained InceptionV3 to train an image classification model. The error that I am facing is during the forward pass in InceptionV3.
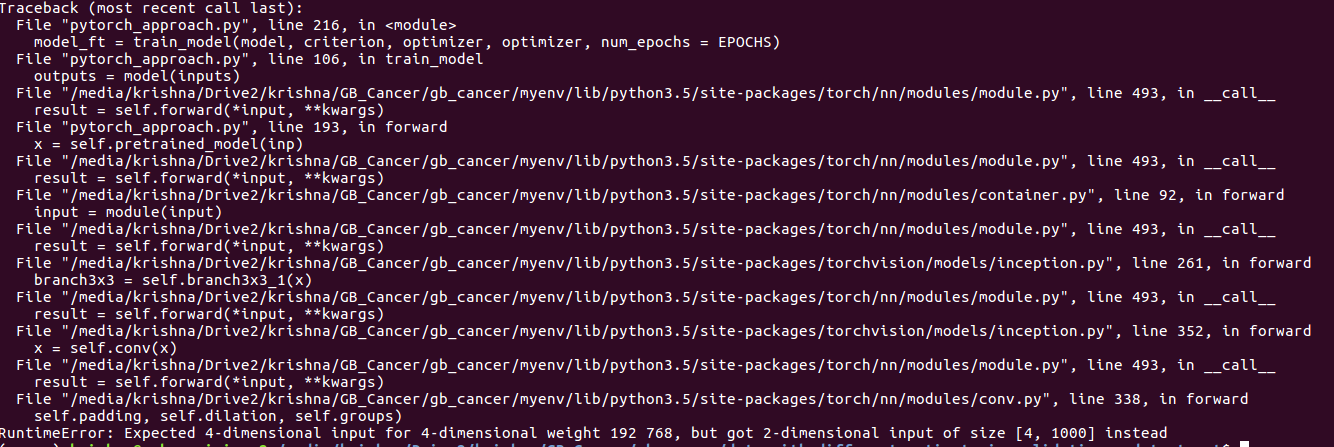
The code that I am using to stack custom layers over the pretrained layers is :
class Custom_Model(torch.nn.Module):
def __init__(self, original_model, p=0.5):
super(Custom_Model, self).__init__()
for param in original_model.parameters():
param.requires_grad = False
original_model.aux_logits = False
temp_list = [*list(original_model.children())]
next_module_in_features = temp_list[-1].in_features
self.pretrained_model = nn.Sequential(*list(original_model.children())[:-1])
self.drop_layer_1 = nn.Dropout(p=p)
self.fc_1 = nn.Linear(next_module_in_features, 64)
self.drop_layer_2 = nn.Dropout(p=p)
self.fc_2 = nn.Linear(64, 3)
def forward(self, inp):
print("The size of the tensor recieved is : {}".format(inp.size()))
x = self.pretrained_model(inp)
x = self.drop_layer_1(x)
x = F.relu(self.fc_1(x))
x = self.drop_layer_2(x)
x = F.softmax(self.fc_2(x))
return x
Where the original model is torchvision.models.inception_v3(pretrained = True)
The way I am calling this custom model from the main function is :
if __name__=='__main__':
model_ft = models.inception_v3(pretrained = True)
model = Custom_Model(model_ft)
for child in model.children():
print(child)
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr = 0.001)
model = train_model(model, criterion, optimizer, optimizer, num_epochs = EPOCHS)
torch.save(model.state_dict(), 'Transfer_learning_Inception_V3_final.pt')
I have also ensured that the input that goes into the original_model is correct and the size of the tensor is (2, 3, 299, 299) → the standard size required by InceptionV3.
What can be the reason behind this error?