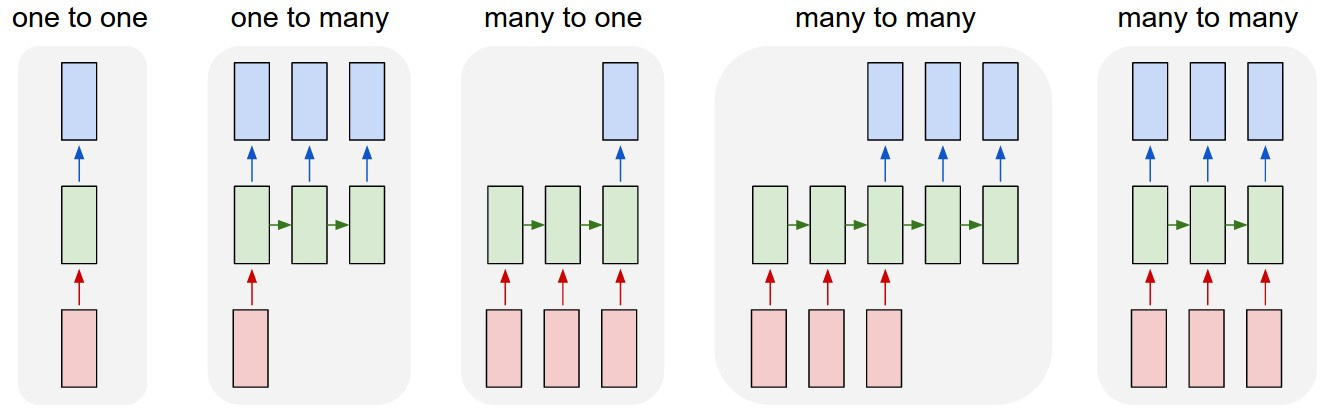
The Pytorch RNN implementation confused me very badly! but I guess I finally figured it out.
First of all, lets see how a simple RNN does its job. The formula for a vanilla RNN is as follows:
$$ h_t = tanh(W_1 . X_t +W_2 . h_{t-1}) $$
This as we all know is the formula to calculate the new hidden state, for the output part!, however a second step is needed, which is as follows :
$$ o_t = softmax(W_3 \cdot h_t ) $$
W_3 has the shape of (output_size, hidden_size) which after being multiplied by hidden_state (h_t witch shape of (hiddensize, 1) will result in the output vector of shape (outputsize, 1).
Pytorch, doesnt calculate the output by default, so it is up to the user to write it down! RNNs in Pytorch return two results one usually called output and theother hiddenstate, what it really returns as output is actually all the hidden_states for all the timesteps (first result) and the final hidden_state as the second result. This is also the case for LSTM!
This is also indicated in the documentation as it reads :
# the first value returned by LSTM is all of the hidden states throughout
# the sequence. the second is just the most recent hidden state
# (compare the last slice of "out" with "hidden" below, they are the same)
# The reason for this is that:
# "out" will give you access to all hidden states in the sequence
# "hidden" will allow you to continue the sequence and backpropagate,
# by passing it as an argument to the lstm at a later time
So how do we do it in Pytorch then?
So basically in order to have the output of your choice you should have a nn.Linear module with the specified output size as its out_features and hiddensize as its in_features .
So basically lets say, we want a havea many to many RNN configuration.
Our input dim is 26, our output is 26 as there are 26 letters in the alphabet for the sake of our example, (both one hot encoded), and our hidden_size is lets say 100. we would then write :
class ou_rnn(nn.Module):
def __init__(self, input_dim, output_dim, hidden_size, num_layer):
super().__init__()
self.rnn = nn.RNN(input_size = input_dim, hidden_size = hidden_size, num_layers = num_layer)
# you specify your output size in the linear model.
self.fc = nn.Linear(hidden_size, output_dim)
def forward(self, x, h):
out,h = self.rnn(x,h)
out = out.contiguous().view(-1, hidden_size)
out = self.fc(out)
return out,h
and in the training loop, the only thing that needs to be taken care of is the labels (they should be reshaped as well to have the shape label.view(batch_size * sequence_length) when used in CrossEntropyLoss
Thats it!
As you can see, you can easily have any kind of RNN(or LSTM) configuration. many to many, or many to one, or what ever!
IMHO, the source for all of these issues is the misleading naming that is being used in Pytorch. instead of calling all the hidden_states as outputs, simply refer to them as all_hidden_states!
Hope this is useful.
in case there is something that I missed, please correct me.
I also found this to be very helpful