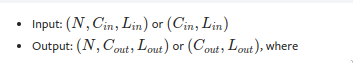Error
Exception has occurred: RuntimeError
Given groups=1, weight of size [32, 13, 1], expected input[1, 32, 13] to have 13 channels, but got 32 channels instead
Doubt
The same data processing works fine for the Linear GAN Model but when I create a Convolutional 1D model for GANs it gives me this error And if I change the z=13 (noise_size for GANs), it gives me different errors related to the size of the model.
1D Convolutional GAN Model
import torch
import torch.nn as nn
#Hyperparameters etc.
device = "cuda" if torch.cuda.is_available() else "cpu"
#noise_size =13
batch_size = 32
class Generator(nn.Module):
def __init__(self,features_in):
super(Generator,self).__init__()
noise_size=features_in
self.hid0 = nn.Sequential(
nn.Conv1d(noise_size, 32, 1, stride=2),
nn.BatchNorm1d(noise_size),
nn.ReLU()
)
self.hid1 = nn.Sequential(
nn.Conv1d(32,64, 1, stride=2),
nn.ReLU()
)
self.hid2 = nn.Sequential(
nn.Conv1d(64,128, 1, stride=2),
nn.ReLU()
)
self.out = nn.Sequential(
nn.Conv1d(128, noise_size,1, stride=2),
nn.Tanh()
)
def forward(self, x):
x = self.hid0(x)
x = self.hid1(x)
x = self.hid2(x)
x = self.out(x)
return x
class Discriminator(nn.Module):
def __init__(self,features_in):
super(Discriminator, self).__init__()
noise_size=features_in
self.hid0= nn.Sequential(
nn.Conv1d(noise_size, 256, 1, stride=2),
nn.BatchNorm1d(256),
nn.LeakyReLU(0.2),
#nn.Dropout(0.3)
)
self.hid1= nn.Sequential(
nn.Conv1d(256, 128, 1, stride=2),
nn.BatchNorm1d(128),
nn.LeakyReLU(0.2),
# nn.Dropout(0.3)
)
self.hid2= nn.Sequential(
nn.Conv1d(128, 64, 1, stride=2),
nn.BatchNorm1d(64),
nn.LeakyReLU(0.2),
nn.Dropout(0.3)
)
self.out= nn.Sequential(
nn.Conv1d(64,1, 1, stride=2),
nn.BatchNorm1d(1),
nn.Sigmoid(),
)
def forward(self, x):
x=self.hid0(x)
x=self.hid1(x)
x=self.hid2(x)
x=self.out(x)
return x
Data Processing
#CASE 1: HIV REAL VS HIV FAKE(GENERATED DATA880) TO THE DICRIMINATOR
import re
from dynamic_dataset_processing import *
import pickle
import pandas as pd
from sklearn.metrics import accuracy_score
import torch
from torch import nn
import numpy as np
from GAN_model_3 import *
from torch.utils.data import TensorDataset
from sklearn.preprocessing import MinMaxScaler,StandardScaler
import matplotlib.pyplot as plt
from matplotlib import pyplot
batch_size = 32
#noise_size=35
#device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
"""Processing dataset for GANs"""
def to_gan_input(dataset,batch_size):
#partition of the dataset
df=dataset.astype('float32')
#division in training ans test 75/25
n_train_data = df[:int(dataset.shape[0]*0.8),:]
n_test_data = df[int(dataset.shape[0]*0.8):,:]
#normalization of the data
scaler = MinMaxScaler()
#Here we are dividing the seq_len and num_vars separately since its a 4d data
seq_len=n_train_data.shape[1]
num_vars=n_train_data.shape[2]
n_train_data=np.reshape(n_train_data,(n_train_data.shape[0],num_vars * seq_len))
n_test_data=np.reshape(n_test_data,(n_test_data.shape[0],num_vars * seq_len))
scaler.fit(n_train_data)
#to scale the values between 0 and 1
n_train_data = scaler.transform(n_train_data)
n_test_data = scaler.transform(n_test_data)
#collects data in batches of batch size=32
train_dataloader = torch.utils.data.DataLoader(n_train_data.astype('float32'), batch_size=batch_size, shuffle=False)
test_dataloader = torch.utils.data.DataLoader(n_test_data.astype('float32'), batch_size=batch_size, shuffle=False)
return n_train_data,n_test_data,train_dataloader,test_dataloader,scaler,seq_len
"""Batch training"""
def train_batch(real_samples, generator, discriminator, optimizer_g, optimizer_d,criterion,noise_size):
#real_samples=torch.unsqueeze(real_samples,0)
#shape = size or gives the number of rows in a 2d array of real samples
bsz = real_samples.size(0) #bsz=32
#bsz=dynamic_dataset.shape[-1]
#labels for classification of the discriminator
label_real = torch.tensor(np.ones((bsz,1))).float()
label_fake = torch.tensor(np.zeros((bsz,1))).float()
"""#OPTIMIZACION the GENERATOR"""
# Reset gradients: Zero your gradients for every batch!
optimizer_g.zero_grad()
# Generate fake samples - create noisy input in float
z = torch.randn(bsz,noise_size)
# z_shape=z.size()
fake_samples = generator(z) #[32,16,1]
# Evaluation of the data by the discriminator or it gives the probability of the data being real
predictions_g_fake = discriminator(fake_samples).float()
# We compute the generator error
#criterion(input,target)
loss_g = criterion(predictions_g_fake, label_real)
loss_g_return=loss_g
# Backpropagate
loss_g.backward()
# We update weights
optimizer_g.step()
"""#OPTIMIZATION OF THE DISCRIMINATOR"""
# Detach the fake samples to be able to train the discriminator
fake_samples = fake_samples.detach()
# Reset gradients
optimizer_d.zero_grad()
# predictions of the descriminator on the real samples
predictions_d_real = discriminator(real_samples).float()
# Error respecto a real samples discrimination
loss_d_real = criterion(predictions_d_real, label_real)
acc_d_real=accuracy_score(predictions_d_real.round().detach(), label_real)
# predictions of the descriminator on the fake samples
predictions_d_fake = discriminator(fake_samples).float()
#Error respecto a fake samples discrimination
loss_d_fake = criterion(predictions_d_fake, label_fake)
acc_d_fake=accuracy_score(predictions_d_fake.round().detach(), label_fake)
# Total discriminator loss
loss_d = (loss_d_real + loss_d_fake) / 2
loss_d_return=loss_d
loss_d.backward()
acc_d=(acc_d_real + acc_d_fake) / 2
# Actualizar pesos del discriminador
optimizer_d.step()
return loss_g_return.item(), loss_d_return.item(),acc_d.item()
"""Obtain the datasets"""
#get the dataset
#f=open('SMOTE_univar_VOLAD_HIV_10_years_cnn2.pickle','rb')
#f=open('SMOTE_univar_VOLAD_non_HIV_10_years_cnn2.pickle','rb')
#f=open("SMOTE_multivar_VOLAD_HIV_CD4_7_years_cnn.pickle",'rb')
f=open("SMOTE_multivar_VOLAD_non_HIV_CD4_7_years_cnn.pickle",'rb')
dynamic_dataset=pickle.load(f)
#For CD4=1 for VLOAD use below 0
dynamic_dataset=dynamic_dataset[:,0,:,:]
#dynamic_dataset=np.squeeze(dynamic_dataset,1)
dynamic_dataset=np.expand_dims(dynamic_dataset,3)
#procesing for the vload dataset
n_train_data,n_test_data,train_dataloader,test_dataloader,scaler,pred_samples=to_gan_input(dynamic_dataset,batch_size)
#Definition of hyperparameters
num_epochs = 50
lr = 0.0002
betas = (0.5, 0.999)
features=8
num_classes = 2
features_in=dynamic_dataset.shape[1] #13
noise_size=features_in #13
clean=True
"""Model Definition for Linear GAN, optimizers and loss"""
generator = Generator(features_in)
optimizer_g = torch.optim.Adam(generator.parameters(), lr=lr, betas=betas)
discriminator = Discriminator(features_in)
optimizer_d = torch.optim.Adam(discriminator.parameters(), lr=lr, betas=betas)
criterion = nn.BCELoss()
"""TRAIN"""
running_g_loss=0.0
running_d_loss=0.0
g_loss_array=[]
d_loss_array=[]
acc_d_array=[]
for epoch in range(num_epochs):
for i, data in enumerate(train_dataloader):
real_samples=data
real_samples_len=len(data)
loss_g, loss_d,acc_d = train_batch(real_samples, generator, discriminator, optimizer_g, optimizer_d,criterion,noise_size)
running_g_loss+=loss_g
running_d_loss+=loss_d
aux=len(train_dataloader)
if((i+1) % len(train_dataloader)==0):
g_loss_array.append(running_g_loss/aux)
d_loss_array.append(running_d_loss/aux)
acc_d_array.append(acc_d)
print(f"\nEpoch: {epoch+1}/{num_epochs}, batch: {i+1}/{len(train_dataloader)}, G_mean_batch_loss: {running_g_loss/aux}, D_mean_batch_loss: {running_d_loss/aux},D_accu last batch:{acc_d}")
running_g_loss=0.0
running_d_loss=0.0
epoch_count = range(1, len(g_loss_array) + 1)
plt.suptitle('GANS: Generator & Discriminator loss for VLOAD patients with Non-HIV')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.plot(epoch_count, g_loss_array,label='generator loss')
plt.show()
plt.plot(epoch_count, d_loss_array,label='discriminator loss')
plt.legend()
plt.show()
plt.close()
epoch_count = range(1, len(acc_d_array) + 1)
plt.suptitle('GANS: Discriminator Accuracy for VLOAD patients with Non-HIV')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.plot(epoch_count, acc_d_array)
plt.show()
Linear GAN Model
import torch
import torch.nn as nn
# Hyperparameters etc.
device = "cuda" if torch.cuda.is_available() else "cpu"
#noise_size =13
batch_size = 32
class Generator(nn.Module):
def __init__(self,features_in):
super(Generator,self).__init__()
noise_size=features_in
self.gen = nn.Sequential(
nn.Linear(noise_size, 64),
nn.LeakyReLU(0.01),
nn.Linear(64,noise_size),
nn.Tanh(), # normalize inputs to [-1, 1] so make outputs [-1, 1]
nn.BatchNorm1d(noise_size),
nn.ReLU()
)
def forward(self, x):
return self.gen(x)
class Discriminator(nn.Module):
def __init__(self,features_in):
super(Discriminator, self).__init__()
noise_size=features_in
self.disc = nn.Sequential(
nn.Linear(noise_size, 64),
nn.BatchNorm1d(64),
nn.ReLU(),
nn.Linear(64, 128),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Linear(128, 64),
nn.BatchNorm1d(64),
nn.ReLU(),
nn.Linear(64, 1),
nn.BatchNorm1d(1),
nn.Sigmoid(),
)
def forward(self, x):
return self.disc(x)