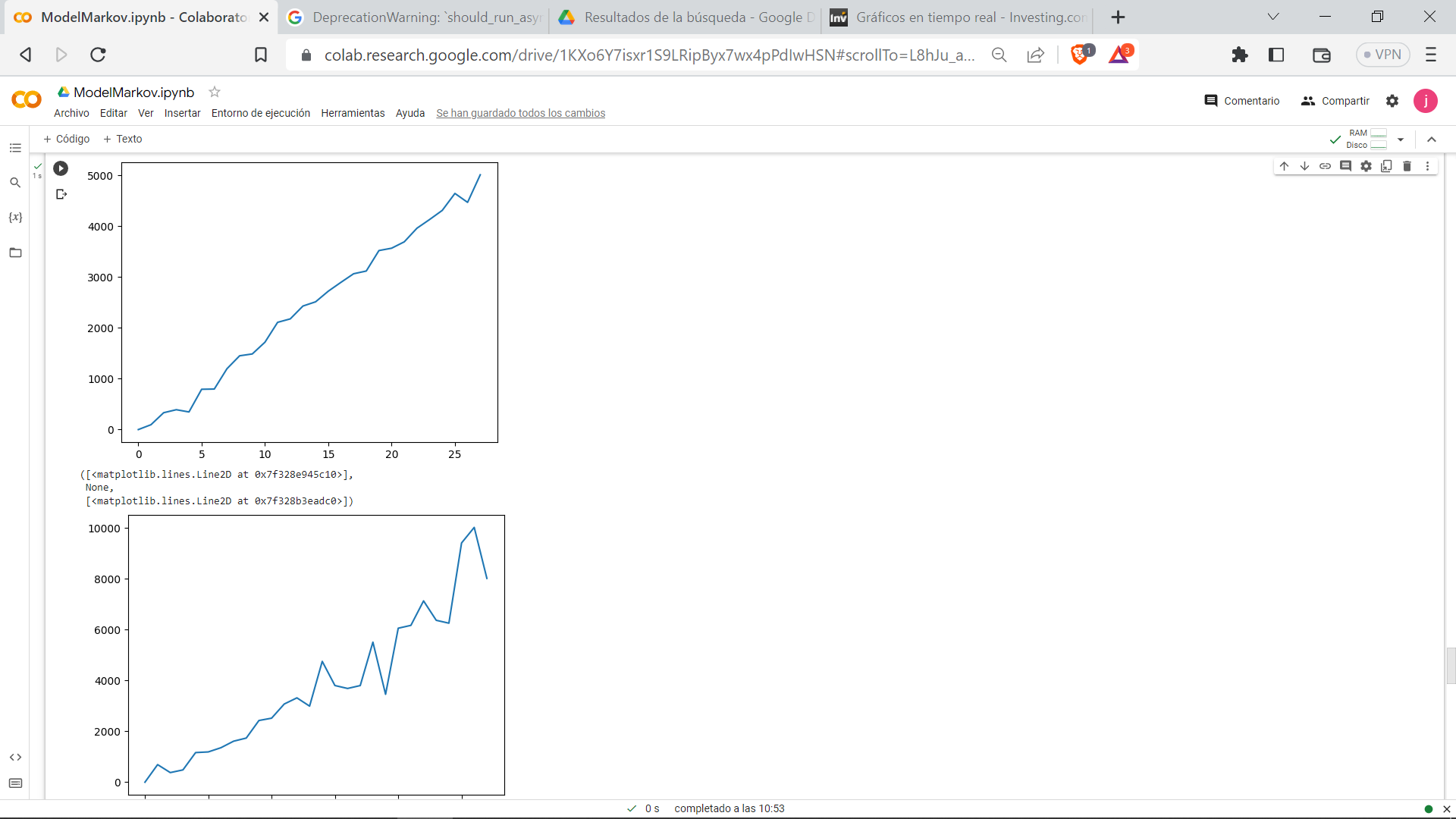
I use pytorch 1.13.1+cu116 and I have a gradient problem I have tried to modify the learning rate, initialize the weights of the network, change the weights of the network, normalize the data as the weights, and I still have this problem of gradient explosive I have done everything but this problem does not disappear, I have written the model in a different way and the problem is not solved. I apply this in TD3 DDPG.
My code,
import copy
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)
Implementation of Twin Delayed Deep Deterministic Policy Gradients (TD3)
Paper: [1802.09477] Addressing Function Approximation Error in Actor-Critic Methods
class Actor(nn.Module):
def init(self, state_dim, action_dim, max_action):
super(Actor, self).init()
self.l1 = nn.Linear(state_dim, 256)
self.l2 = nn.Linear(256, 256)
self.l3 = nn.Linear(256, action_dim)
self.max_action = max_action
def forward(self, state):
a = F.relu(self.l1(state))
a = F.relu(self.l2(a))
return self.max_action * torch.tanh(self.l3(a))
class Critic(nn.Module):
def init(self, state_dim, action_dim):
super(Critic, self).init()
# Q1 architecture
self.l1 = nn.Linear(state_dim + action_dim, 256)
self.l2 = nn.Linear(256, 256)
self.l3 = nn.Linear(256, 1)
# Q2 architecture
self.l4 = nn.Linear(state_dim + action_dim, 256)
self.l5 = nn.Linear(256, 256)
self.l6 = nn.Linear(256, 1)
def forward(self, state, action):
sa = torch.cat([state, action], 1)
q1 = F.relu(self.l1(sa))
q1 = F.relu(self.l2(q1))
q1 = self.l3(q1)
q2 = F.relu(self.l4(sa))
q2 = F.relu(self.l5(q2))
q2 = self.l6(q2)
return q1, q2
def Q1(self, state, action):
sa = torch.cat([state, action], 1)
q1 = F.relu(self.l1(sa))
q1 = F.relu(self.l2(q1))
q1 = self.l3(q1)
return q1
class TD3(object):
def init(
self,
state_dim,
action_dim,
max_action,
discount=0.99,
tau=0.005,
policy_noise=0.2,
noise_clip=0.5,
policy_freq=2
):
self.actor = Actor(state_dim, action_dim, max_action).to(device)
self.actor_target = copy.deepcopy(self.actor)
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=3e-4)
self.critic = Critic(state_dim, action_dim).to(device)
self.critic_target = copy.deepcopy(self.critic)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=3e-4)
self.max_action = max_action
self.discount = discount
self.tau = tau
self.policy_noise = policy_noise
self.noise_clip = noise_clip
self.policy_freq = policy_freq
self.total_it = 0
def select_action(self, state):
state = torch.FloatTensor(state.reshape(1, -1)).to(device)
return self.actor(state).cpu().data.numpy().flatten()
def train(self, replay_buffer, batch_size=256):
self.total_it += 1
# Sample replay buffer
state, action, next_state, reward, not_done = replay_buffer.sample(batch_size)
with torch.no_grad():
# Select action according to policy and add clipped noise
noise = (
torch.randn_like(action) * self.policy_noise
).clamp(-self.noise_clip, self.noise_clip)
next_action = (
self.actor_target(next_state) + noise
).clamp(-self.max_action, self.max_action)
# Compute the target Q value
target_Q1, target_Q2 = self.critic_target(next_state, next_action)
target_Q = torch.min(target_Q1, target_Q2)
target_Q = reward + not_done * self.discount * target_Q
# Get current Q estimates
current_Q1, current_Q2 = self.critic(state, action)
# Compute critic loss
critic_loss = F.mse_loss(current_Q1, target_Q) + F.mse_loss(current_Q2, target_Q)
# Optimize the critic
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# Delayed policy updates
if self.total_it % self.policy_freq == 0:
# Compute actor losse
actor_loss = -self.critic.Q1(state, self.actor(state)).mean()
# Optimize the actor
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# Update the frozen target models
for param, target_param in zip(self.critic.parameters(), self.critic_target.parameters()):
target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data)
for param, target_param in zip(self.actor.parameters(), self.actor_target.parameters()):
target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data)
def save(self, filename):
torch.save(self.critic.state_dict(), filename + "_critic")
torch.save(self.critic_optimizer.state_dict(), filename + "_critic_optimizer")
torch.save(self.actor.state_dict(), filename + "_actor")
torch.save(self.actor_optimizer.state_dict(), filename + "_actor_optimizer")
def load(self, filename):
self.critic.load_state_dict(torch.load(filename + "_critic"))
self.critic_optimizer.load_state_dict(torch.load(filename + "_critic_optimizer"))
self.critic_target = copy.deepcopy(self.critic)
self.actor.load_state_dict(torch.load(filename + "_actor"))
self.actor_optimizer.load_state_dict(torch.load(filename + "_actor_optimizer"))
self.actor_target = copy.deepcopy(self.actor)