Now, I have a problem with my work. I dont find any solution for it.
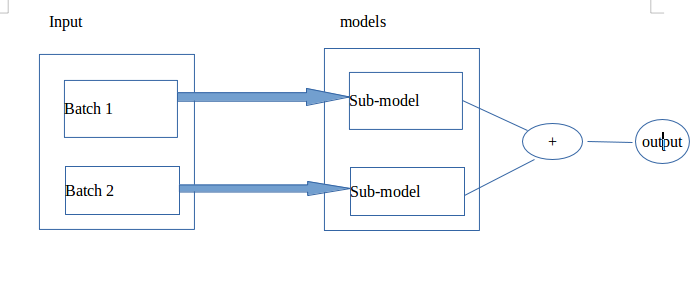
I want to implement one model like behind image. It will run on single GPU.
My inputs are extended more one dimensions (5 dimensions instead of 4 ). In models, there is 2 submodels. Each submodel has one inputs like my image.
I have to implement 2 submodels which run parallelly to improve performance.
I try to use multhreading on one GPU but the time is the same with sequential models.
It’s the same for the backward method, it uses cuda calls that are asynchronous, so it will run in parallel if you GPU allows it.
On a single gpu, whenever you ask for something to be done on the gpu, it is added to a stack and returns. So if you do a lot of operations, the only thing that you do is add all of them to the stack. What the gpu is doing, is as soon as it has free compute, it takes the next item in the stack and execute it. So if your gpu has spare compute, it will always run as many stuff at the same time as possible.
With second question, with same input for 2 submodels. I think with same input, net2 has to wait the input in1 which net1 is using (althought GPU can enough compute available). Then, it is not parallel. Is it true?
In theory if your gpu has enough compute, then running all 3 will be the same as running 1 yes.
It is really unlikely that your gpu will have enough compute to do that.
Also if you start measuring time by looking how long it took to run a python code line, keep it mind that the api is asynchronous which means it is not because the line executed that the code actually ran on the gpu. If you want to wait for all operations to finish on the gpu, use torch.cuda.synchronize().
I am using GeForce GTX 1080 Ti. I test with small models( about 40000 parameters). I think, my GPU can enough compute. I also use the @profiler to measure time. The result :
Timer unit: 1e-06 s
Line # Hits Time Per Hit % Time Line Contents
204 4689 5770628.0 1230.7 13.0 output_2 = net_1(data);
205 4689 2219502.0 473.3 5.0 output_1 = net(data);
206 4689 2166653.0 462.1 4.9 output_3 = net_2(data);
207 4689 2156971.0 460.0 4.9 output_4 = net_3(data);
Running with 1 command line:
Line # Hits Time Per Hit % Time Line Contents
204 4689 5422347.0 1156.4 18.9 output_2 = net_1(data);
i think the total time is not the same.
This means: this doesn’t run in parallel
The timing you just did are not correct, you just measure how long it takes to add the task to the stack of job for the gpu, which is going to be more or less the same for all your nets.
The conclusion your have “this doesn’t run in parallel” is wrong: you don’t actually measure the execution time in your timing. To measure proper runtime, you need to add torch.cuda.synchronize() to force the python code to wait for the gpu to finish executing everything.
When I understand correctly, you said that operations are added to a stack and then given to the GPUs when computing resources become available. So, when you mentioned that the CUDA api is asynchronous by default, it would only run things in parallel if the inputs don’t have dependencies in the graph that were not previously satisfied?
Or in other words, in this code scenario above, even with 2 GPUs, it would wait until out1 is computed before out2 gets computed. That makes sense.
So, basically, the advantage of using 2 GPUs in PyTorch is that is simple extends the pool of computing resources available but does not affect the order in which the operations are processes. For instance, this could be useful if e.g., one giant matrix multiplication would be too large for one GPU, so the computing resources from the 2 GPUs could be pooled to compute the dot products in parallel?
All the discussion here was for 1 GPU.
If you have 2 GPUs, then it is more complex, as you will need to manually assign the different tasks to the different operations. This cannot be done automatically.
Oh I see, I was somehow getting threads mixed up. What you say is also what I assumed, so I was briefly positively surprised about the possibility that it would automatically extend the pool of computing resources as (i.e., as if you would have one GPU with 2x the computing resources)
Then that means that your gpu is not able to run all 3 at the same time. You can check that by using nvidia-smi and check the gpu compute usage when using a single of these nets. If it is already 100%, then I would expect that you get no much speedup.