Hello everyone,
I’m working on some custom PyTorch modules and autograd.Functions that I want to integrate into the PyTorch backward graph. My computation requires interfacing with third-party software for which I need to change the data type of the tensor to NumPy arrays for the forward method. The grad_input of the backward method of my custom autograd.Function receives a tuple of non-tensor objects, namely an scipy interpolator object which should be evaluated at the points of the forward output. Unfortunately, passing the interpolator object to the backward seems to cause problems and autograd.backward throws a type error. How do I get around this restriction? Ofc, all computations would only be done on CPU etc.
From the extending Torch tutorial, I took away that this should be possible but it is not explicitly shown how to do it:
“In general, implement a custom function if you want to perform computations in your model that are not differentiable or rely on non-Pytorch libraries (e.g., NumPy), but still wish for your operation to chain with other ops and work with the autograd engine.”
Thanks for any hints and help on this!
Can you share a minimal reproducible example of this custom function? If you pass an interpolator in the forward method, you’ll need to explicitly define a derivative for it in the backward pass which may be a problem.
Thanks for your reply:
class some_function(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
output1 = input
output2 = input
ctx.save_for_backward(input)
return output1, output2
@staticmethod
def backward(ctx, grad_input1:Tensor, grad_input2:Interpolator):
forward_input = ctx.saved_tensors()
grad_output1 = grad_input1
grad_output2 = grad_input2.interpolate(forward_input.numpy())
grad_output2 = torch.tensor(grad_output2)
return grad_output1 + grad_output2
The forward doesn’t really do anything except splitting the input, one part to another pytorch nn.module and the other to the third-party software.
The interpolator is returned only for the backward, and this is where the problem arises since .backward seems not to accept other inputs then Tensor or None
Ok, so there’s a few issues that I can see. Firstly, when you define a function to have 2 outputs, you’ll always have 2 arguments (excluding ctx) within the backward method. These values will correspond to the grad_output NOT the grad_input. The grad_input is what you have to manually define. The grad_output represents the gradient of the loss with respect to the output of the forward pass.
In the backward method, you’ll need to define the gradient of the output with respect to the input, and as you have one input you’ll return one grad_input (which you do).
The grad_output terms are always torch.Tensor objects, so passing grad_output2 as type Interpolator will cause issues. Which explains the issue you mentioned,
Also, I’m not 100% sure about your derivative definition when you add both grad_input1 and grad_input2 together. Perhaps it might be easier to just define the interpolator as a custom function and leave output1 as just torch.clone()?
Anyway… you’ll need to make the appropriate changes to the example code below, but here’s a rough idea of what the function should look like
import torch
from torch import Tensor
Interplator = your_interpolator_class()
class some_function(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
output1 = input
output2 = input
ctx.save_for_backward(input)
return output1, output2
@staticmethod
def backward(ctx, grad_output1: Tensor, grad_output2: Tensor):
input, = ctx.saved_tensors #returns the input as tuple include "," to unpack it, also no () needed either
grad_input1 = grad_output1 #dropping the *1 for clarity
input_np = input.cpu().detach().numpy() #pass to numpy on CPU
output_np = Interplator.interpolate(input_np)
grad_input2 = torch.from_numpy(output_np)
return grad_input1 + grad_input2 #not 100% sure about this, but you can check this.
def func(x):
return some_function.apply(x) #remember to use apply
x = torch.randn(5, requires_grad=True)
out1, out2 = func(x)
loss=torch.mean(out1)
loss.backward()
Thanks a lot for your answer! I think I just used a different description for grad_output but your’re right, the input to the backward are the gradients wrt. the output of the forward.
The problem with the Interpolator class in the way you suggest is that the interpolator is only created in the backward pass. I think I was a bit too sloppy in the way I described it - in essence what I need in the backward is an instanciated RegularGridInterpolator. So creating the class only during the backward wouldn’t work since the points and values arguments of the RegularGridInterpolator object are set by the third party software and I need to evalute the values directly at the input points of the forward.
And directly importing points and values would lead to performance problems, I really want to create this RegularGridInterpolator only once and I will need it in many nodes in the computational Graph. Additionally, the shape of points and values would not match the output shapes of the forward.
Is there a different way to pass an instanciated object to the backward? I like you’re suggestion to supply None as grad_output2 by using
loss=torch.mean(out1)
loss.backward()
Thanks a lot for your help!
I don’t think I follow this,
If you define the interpolater at the beginning of your script (and define your custom function there too) it should be able to use it (like the example above). If you want the interpolator for other functions, I’m not too sure.
When it comes to passing other arguments to torch.autograd.Function, I’m pretty sure you’re restricted to what PyTorch returns. If anyone knows more about this, it’ll be @albanD (apologizes for the tag).
Thanks, I’ll try to make it more clear.
I’m taking the PyTorch functionality a bit out of context because I try to integrate some third-party simulation into my model. The graph that I’m trying to build looks a bit like this:
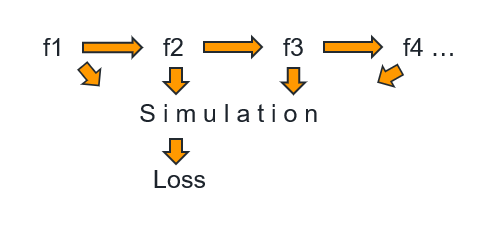
all of the functions f are PyTorch autograd.Functions and the simulation itself also has a backward (not from PyTorch though!) method - it just doesn’t return a tensor but values for the entire simulation environment but on a grid which does not correspond 1:1 to the input values of the functions f. The points where I want to know the values of the simulation are the values at the input points of all of the functions f. Thats why I need to use an RegularGridInterpolator object which returns the values of the simulation at the input points which I can then convert to tensor and then use for backpropagation in the chain of functions f. But its important to stress that the RegularGridInterpolator object really is the grad_output for the backward of the functions f.
But maybe I need to write another custom autograd.Function which takes care of the simulation and the interpolation. It would have been nice and clearer to do it in two steps.
From your figure it looks like the simulation takes in the output of f1, f2, f3, and f4 as inputs so perhaps you could define a torch.autograd.Function with 4 inputs and it returns the output of the simulation method.
I also had a quick google and found this repo which has a PyTorch equivalent version of SciPy’s RegularGridInterpolator: GitHub - sbarratt/torch_interpolations: Interpolation routines in Pytorch.
So maybe you can just use this?
Yes that is probably the way forward for me - I will check out the link to the PyTorch compatible Interpolator, maybe I can also work with this  Thanks for giving me the link to that repo. I was looking for such an Interpolator but didn’t check anywhere else except for the original PyTorch package.
Thanks for giving me the link to that repo. I was looking for such an Interpolator but didn’t check anywhere else except for the original PyTorch package.
Anyway, I think I need to rewrite my architecture a bit and do the interpolation in a different torch.autograd.Function just as you suggested. This will make everything a bit more ugly but I guess I need to bite that bullet.
Thanks a lot for your help, I really appreciated it!