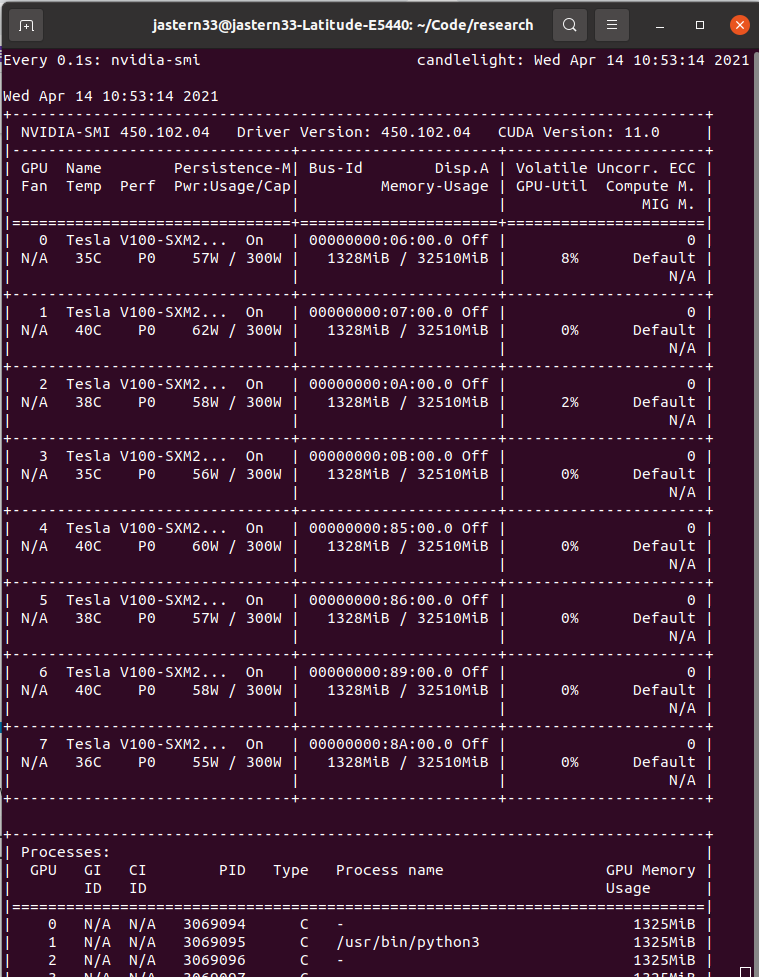
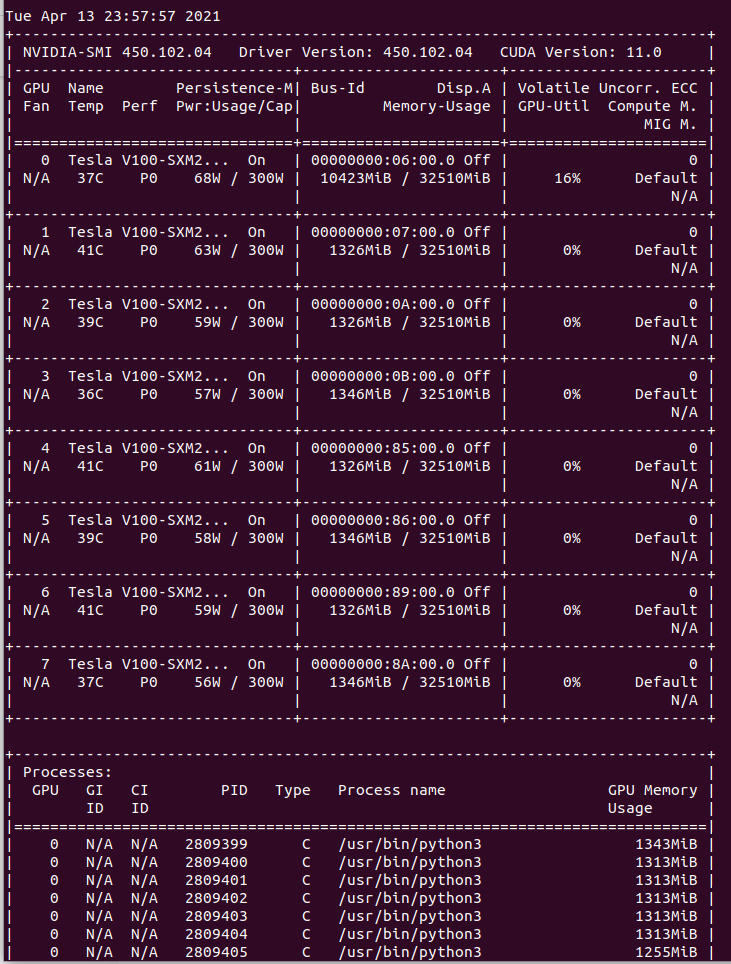
When running the basic DDP (distributed data parallel) example from the tutorial here, GPU 0 gets an extra 10 GB of memory on this line:
ddp_model = DDP(model, device_ids=[rank])
What I’ve tried:
- Setting the ‘CUDA_VISIBLE_DEVICES’ environment variable so that each subprocess can only see the GPU of its rank. Then I set rank = 0.
os.environ['CUDA_VISIBLE_DEVICES'] = str(rank)
rank = 0
setup(rank, world_size)
# etc.
This results in the error
File "/usr/local/lib/python3.8/dist-packages/torch/multiprocessing/spawn.py", line 59, in _wrap
fn(i, *args)
File "/code/test.py", line 49, in demo_basic
setup(rank, world_size)
File "/code/test.py", line 29, in setup
dist.init_process_group("gloo", rank=rank, world_size=world_size)
File "/usr/local/lib/python3.8/dist-packages/torch/distributed/distributed_c10d.py", line 500, in init_process_group
store, rank, world_size = next(rendezvous_iterator)
File "/usr/local/lib/python3.8/dist-packages/torch/distributed/rendezvous.py", line 190, in _env_rendezvous_handler
store = TCPStore(master_addr, master_port, world_size, start_daemon, timeout)
RuntimeError: Address already in use
I also tried rewriting this to use the scripting version of DDP, and saw the same problem.
There is also nothing here involving a profiler, as described here, loading a model from disk, as described here, or calls to torch.cuda.empty_cache, as described here. My machine is a DGX-1 with 8 Tesla V100 GPUs. I tried this on another DGX-1 with the same result.
Any ideas what is consuming so much memory on GPU 0, and how to resolve it?
Screenshot of the problem:
Below is the full MWE, copied from the tutorial:
import os
import sys
import tempfile
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
def demo_basic(rank, world_size):
print(f"Running basic DDP example on rank {rank}.")
setup(rank, world_size)
# create model and move it to GPU with id rank
model = ToyModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(rank)
loss_fn(outputs, labels).backward()
optimizer.step()
cleanup()
def run_demo(demo_fn, world_size):
mp.spawn(demo_fn,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__ == "__main__":
run_demo(demo_basic, torch.cuda.device_count())