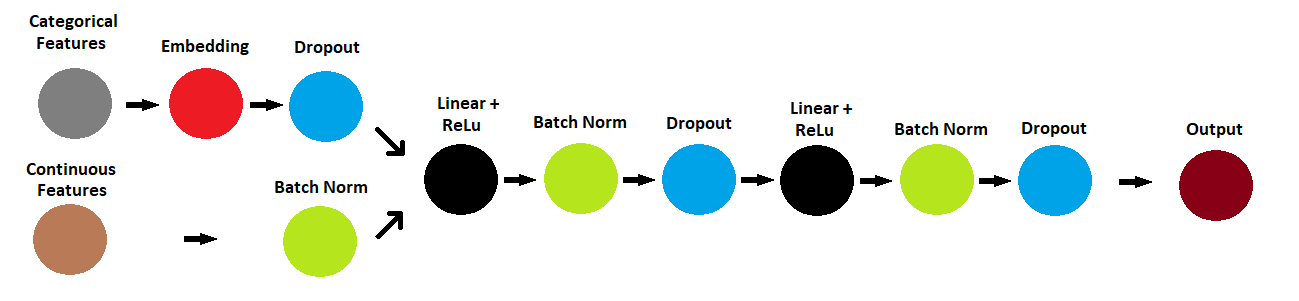
¿How can I extract the feature vectors from my embeddings layers?. If I’m not wrong, these feature vectors are the weights of the layers
¿Can I use the feature vectors to feed them into others models, like Randon Forest?, ¿Do I need a separate trained NN just for the embeddings, so that the can be used in others models?
If I were to train an NN just for the embbedings, ¿wich would be the target variable?. According to above arquitecture, the target needs also the continius features to be predicted.
¿What am I supposed to do in the case, let’s say, that the test/validation set contains a level for some categorical value, wich it’s not present in the training set? In that case, the trained embedding layers won’t have a feature vector for that absent level in test/validation
Depending what you mean by “feature vectors”, you might either access the .weight attribute or use forward hooks to get the activation output of this layer as described here.
Yes, you could store the features and train another model with it. Based on this use case, you would refer to the output activations as features. Otherwise, if you are referring to the .weight parameter, you would only have a single sample and training wouldn’t make sense.
The embeddings would be trained as part of the complete model for your current use case, e.g. a classification. I’m not sure how you would like to train only the embeddings.
I don’t know what the best approach would be for missing tokens.
Yes, I want to extract the weights of the embeddings layers (wich essentialy have captured semantic relationships between the labels o levels of a catagorical feature during the training of my NN) and treat them as feature for a Random Forest model … Obviously, I would use the same originals datasets. The change comes in the form of using the embeddings instead of some other encoder technique (like LabelEncoder or OneHot, wich don’t provide meanindull relationships between the categorical features and its levels). I’ll also use, of course the numerical continius features.
In a nutshell, my new dataset for a Random Forest model would be embeddings + continius features (embeddings replacing categorical features)
Thanks for the explanation.
If I understand the use case correctly, you would like to use the pretrained embeddings to create the continuous output features for categorical inputs and train a new classifier with it?
If so, then this would be supported and you could either store the output activations for all inputs directly using forward hooks or just use the nn.Embedding layer in isolation, feed the input to it, transform the output to numpy arrays, and train your new classifier with it.
If I understand the use case correctly, you would like to use the pretrained embeddings to create the continuous output features for categorical inputs and train a new classifier with it?
YES
If so, then this would be supported and you could either store the output activations for all inputs directly using forward hooks or just use the nn.Embedding layer in isolation, feed the input to it, transform the output to numpy arrays, and train your new classifier with it.
I trained a model using a fully conected NN with embeddings. The target es the column income. The model performs well (you can see the metrics).
But now, I want to use XGBoost and give it a try. However, considering the originals dataset’s, income is predicted using the categorical and continius features. So, I don’t want to use OneHot o similars, because I would be losing the semantic between the categorical features, and that’s why I want to feed the embeddings vectors into XGBoost, with the others continius features obviously. So, my questions are:
Can I just take the weights from my nn.Embedding layers from my model UciAdultsClassifier and feed them into XGBoost? As I said, with also the others continius features. I’m just replacing the form of the categorical features
Do I need to train a separate fully connected NN with just the categorical variables using nn.Embedding layers and predict income? is this correct or the right way of using embeddings vectors in others models than NN’s? Is this approach correct, that is, train a new NN with just nn.Embedding layers to predict income (and not consider the continius features. Danger !!), and then use those embedding vectors or weights to use them in XGBoost?
Your nn.Embedding contains one vector for each category. So of course you would have to repeat it as necessary to fill your dataset. I am just making that clear
Specifically, one embedding vector for every level in each categorical feature. And, for every ocurrence of level (or label, value… whatever) Never-married of the categorical feature marital-status should be replaced by the embedding vector of Never-married