from __future__ import absolute_import
import torch
from torch import nn
from torch.nn import functional as F
import torchvision
class hybrid_cnn(nn.Module):
def __init__(self,**kwargs):
super(hybrid_cnn,self).__init__()
resnet = torchvision.models.resnet50(pretrained=True)
self.base = nn.Sequential(*list(resnet.children())[:-2])
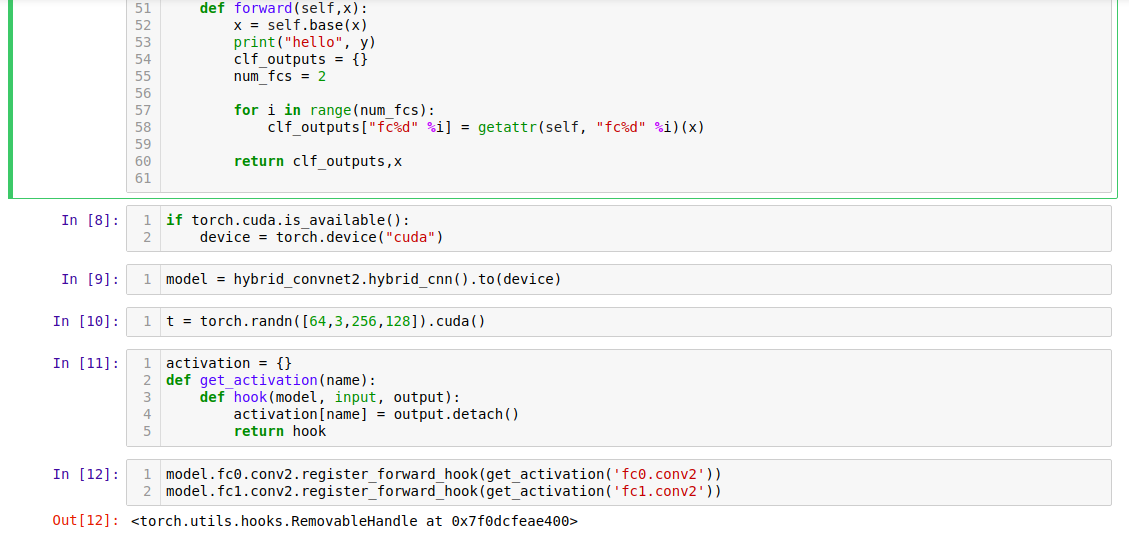
def forward(self,x)
x = self.base(x)
y = self.conv2(self.conv1(x))
clf_outputs = {}
num_fcs = 2
return clf_outputs,x,y
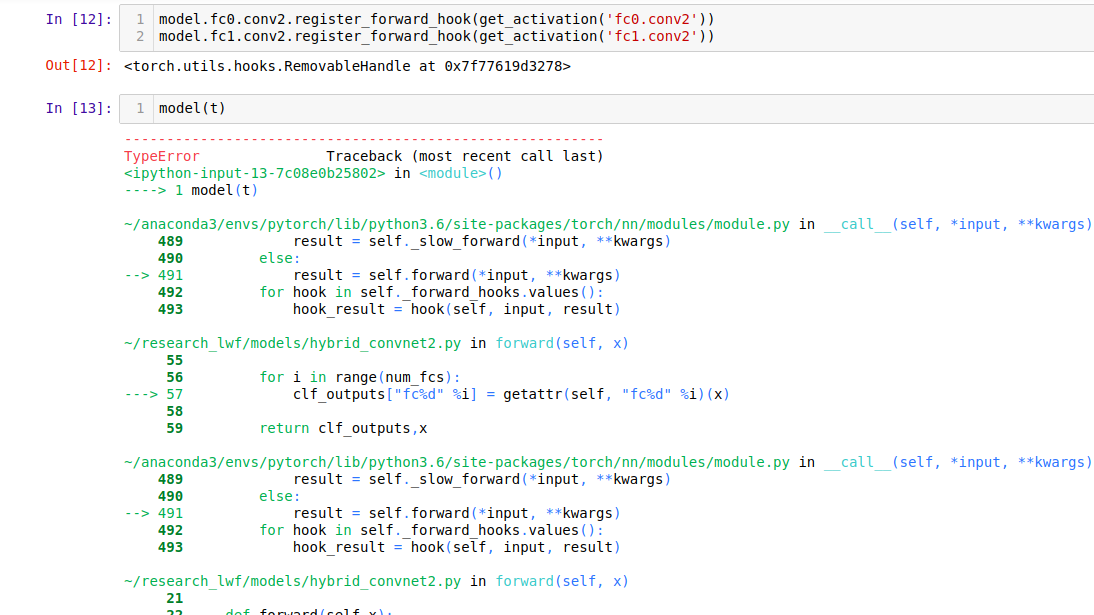
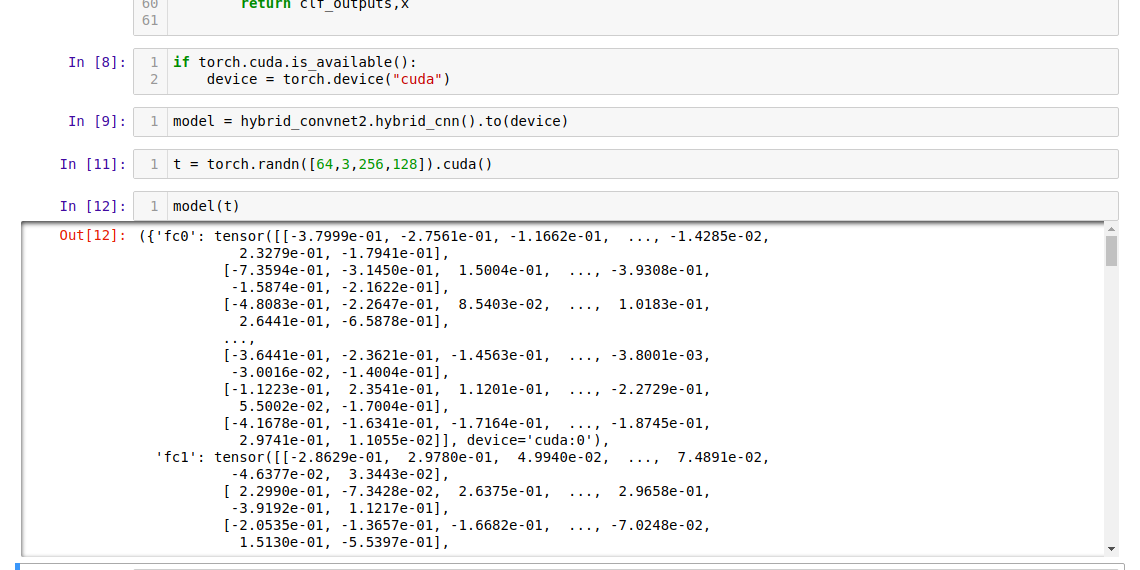
I want a Tensor which would have the output coming from ResNet->conv1->conv2 (classifier layer removed) from both augmented 1 and augmented 2.
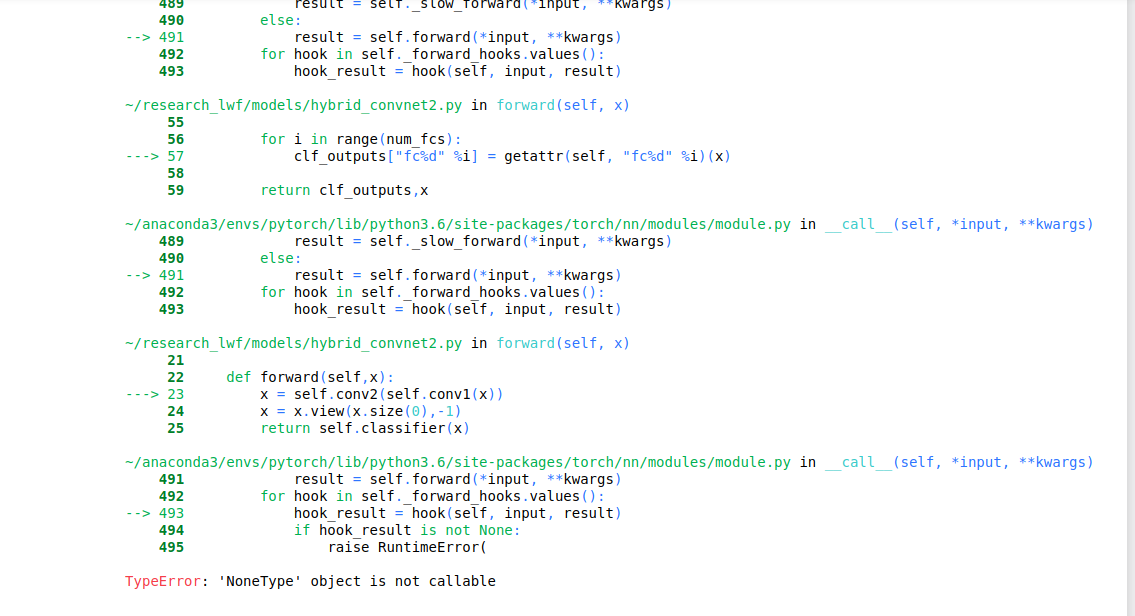
I have tried with register_forward_hook, but removable_hook object is not callable,
. Is there any efficient way to extract features from submodule (output from conv2 layer from both augmented1 and augmented2) ?
I had one another doubt. I wanted to add forbenius norm of covariances with my cross entropy.
i have tried this:
class f_norm(nn.Module):
def __init__(self,epsilon,beta):
super(f_norm,self).__init__()
self.epsilon = epsilon
self.beta = beta
def forward(self, cs,ct):
epsilon=0.1
beta = 0.2
x = self.epsilon*( torch.sqrt((torch.abs(cs-ct))**2)-self.beta)
y = x.view(-1)
y = torch.sum(y)
return y/1000
This doesn’t seem to work, it doesn’t return a Tensor.
I am using this function instead:
def f_norm(cs,ct):
epsilon=0.1
beta = 0.2
x = epsilon*( torch.sqrt((torch.abs(cs-ct))**2)-beta)
y = x.view(-1)
y = torch.sum(y)
return y/1000
loss = cross_entropy(inputs,targets)+f_norm(cs,ct)
If I call loss.backward(), would this work fine ? I read in forums that unless it’s autograd variable it would not be updated. So was having concerns with this implementation.
I’m not sure, why your code outputs strange things, but your code is returning a tensor.
I’ve just removed the unnecessary values (epsilon and beta are defined twice) and it’s working.