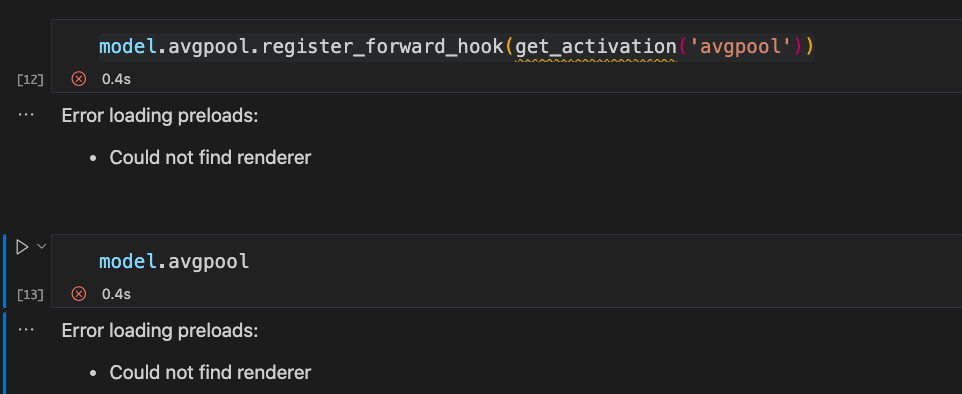
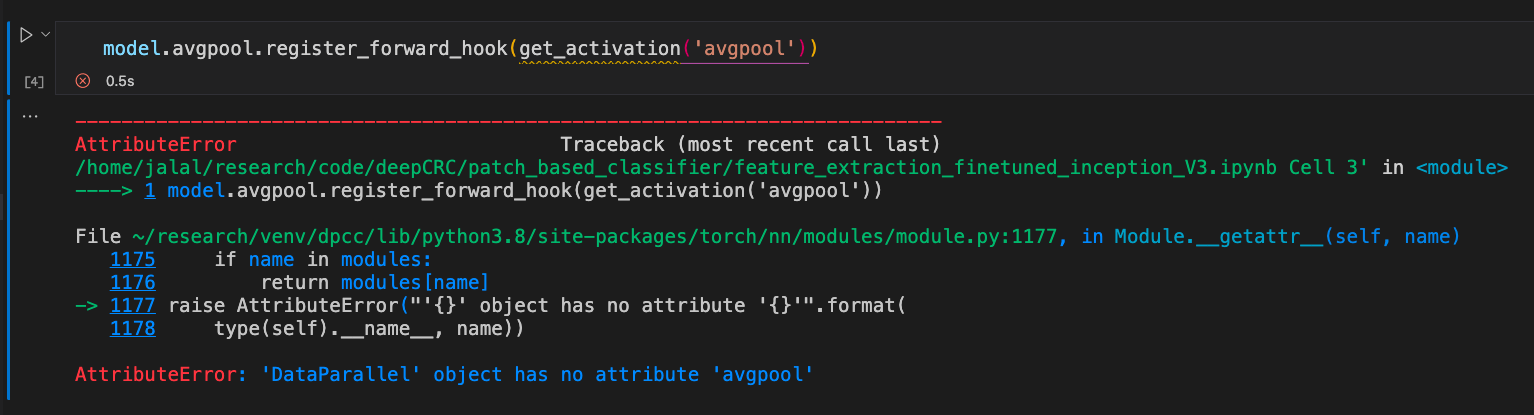
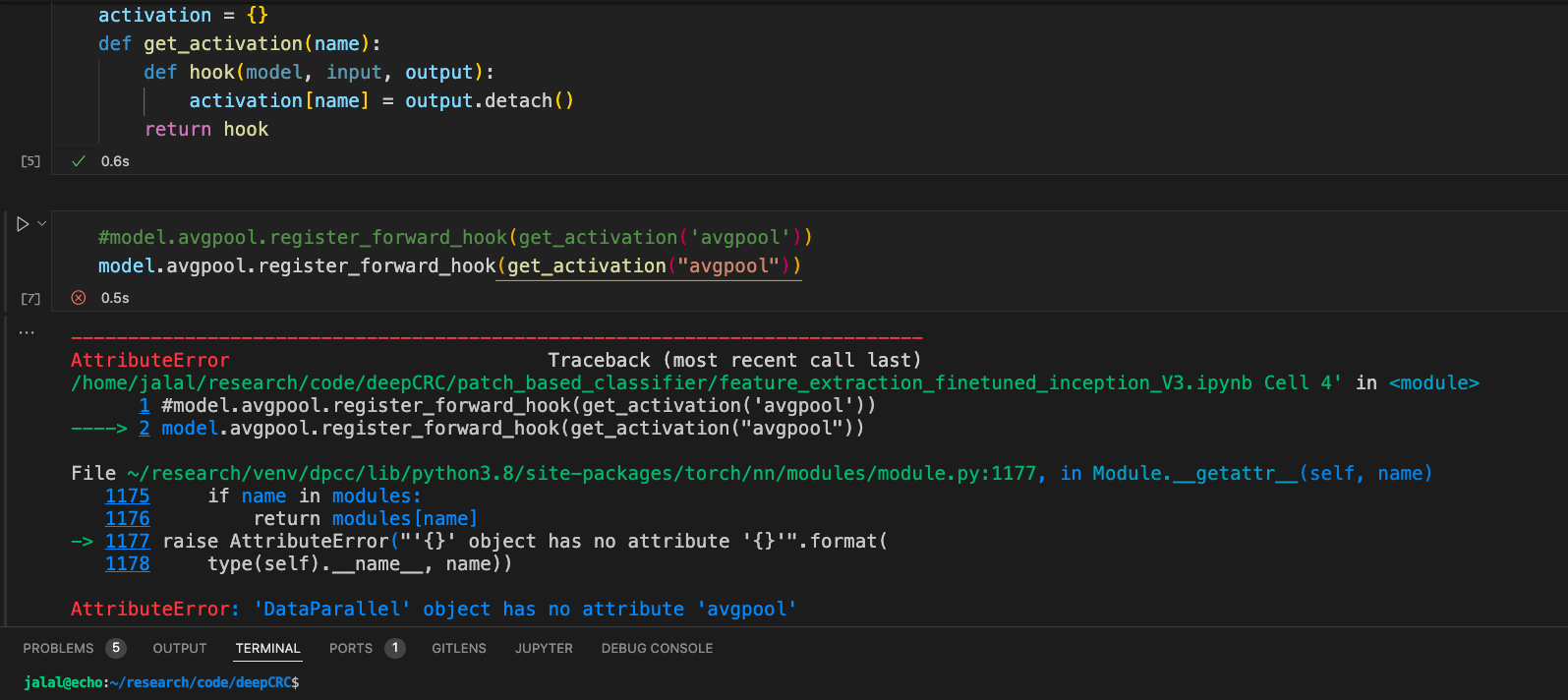
I have already finetuned an Inception V3 model on my dataset which was already pretrained on ImageNet.
Now, I need to load the save pt model and run it on test patches and extract the 2048 feature vector from Inception V3.
I am not sure what code snippet I should use for extracting feature vectors of size 2048 on an inception v3 model that is already finetuned on my own data (train data) on the test set.
import torch
model = torch.load('pt/model_ft_100e_best_acc.pt')
feature_extractor = torch.nn.Sequential(*(list(model.modules())[:-2]))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
batch_size = 1
input_size = 299 # for Inception V3
data_transforms = {
'train': transforms.Compose([
transforms.Resize((input_size, input_size)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.6964, 0.4764, 0.6246], [0.1896, 0.2210, 0.1864])
]),
'val': transforms.Compose([
transforms.Resize((input_size, input_size)),
transforms.ToTensor(),
transforms.Normalize([0.6964, 0.4764, 0.6246], [0.1896, 0.2210, 0.1864])
]),
'test': transforms.Compose([
transforms.Resize((input_size, input_size)),
transforms.ToTensor(),
transforms.Normalize([0.6964, 0.4764, 0.6246], [0.1896, 0.2210, 0.1864])
])
}
data_dir = "/projectnb/ivcgroup/jalal/data/fold1/" # for running on SCC
# Create training and validation datasets
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['test']}
# Create training and validation dataloaders
dataloaders_dict = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True, num_workers=4) for x in ['test']}
sample_fnames_labels = dataloaders_dict['test'].dataset.samples
sample_large_images = {}
test_large_images = {}
test_loss = 0.0
test_acc = 0
with torch.no_grad():
test_running_loss = 0.0
test_running_corrects = 0
print(len(dataloaders_dict['test']))
for i, (inputs, labels) in enumerate(dataloaders_dict['test']):
print(i)
test_input = inputs.to(device)
test_label = labels.to(device)
test_output = feature_extractor(test_input) # here I need to get feature vectors of size 2048
print("test feature size is: ", test_output.shape)