Hello there,
Just into deep learning, and currently I am facing some weird issues regarding the model I am working on. As the title and images below suggest, during training, one of the cpu cores is experiencing extreme kernel usage while other cores barely moves. Despite I am using GPU as the accelerator.

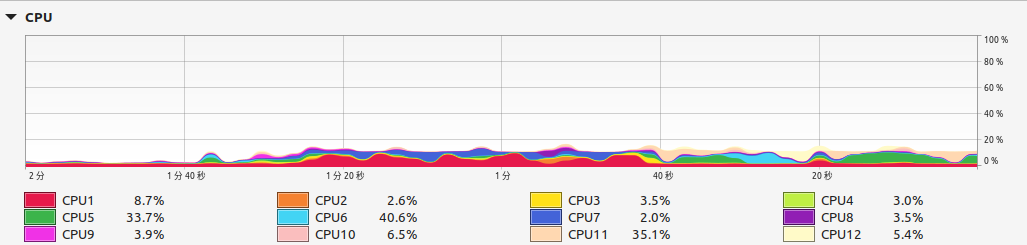
I had read quite a few discussions regarding similar issues, but none fixed my problem.
e.g. CPU usage extremely high
and Very high CPU utilization with pin_memory=True and num_workers > 0 · Issue #25010 · pytorch/pytorch · GitHub
I had tried to set the num_workers in the dataloader to 2 or more, make no difference. Set pin_memory to True or False doesn’t seem to do anything as well.
torch.get_num_threads() returns 6, but torch.set_num_threads() = 6 doesn’t help with the issue.
If I switch the accelerator from cuda to cpu, the model also only uses one cpu core for training, which is extremely inefficient.
The model itself is a Half-UNet for image segmentation, 16bit grey scale image data are converted into tensors in the Dataset, before a variety of transformations got applied and send into the model for training.
Computer Specs:
CPU: Ryzen 5500
GPU: 1050ti
Disks: Data are stored in two 1TB Barracuda HDD in raid 1 using AMD Raid, Operating system and Pycharm are stored in a SSD
Memory: 32GB
Pytorch Version: 1.13.1
Cuda Version: 11.7
Operating System: Linux mint cinnamon
Something interesting I noticed is when I train with my laptop, which has an 11th gen intel i5 (with no discrete graphics) and is running on Windows. The same piece of codes will correctly uses all of the cpu cores of the laptops.
Here is the Dataset class I used:
class Train_Dataset(torch.utils.data.Dataset):
def __init__(self, images_dir, labels_dir):
# Get a list of file paths for images and labels
self.file_list = make_dataset_train(images_dir, labels_dir)
self.num_files = len(self.file_list)
self.img_tensors = []
self.lab_tensors = []
# Pre-allocating the memory for img_tensors and lab_tensors
for idx in range(self.num_files):
# Convert the image and label path to tensors
img_tensor = path_to_tensor(self.file_list[idx][0], label=False)
lab_tensor = path_to_tensor(self.file_list[idx][1], label=True)
lab_tensor = lab_tensor.long()
# Append the tensors to the list
self.img_tensors.append(img_tensor)
self.lab_tensors.append(lab_tensor)
super().__init__()
def __len__(self):
return self.num_files
def __getitem__(self, idx):
# Get the image and label tensors at the specified index
img_tensor = self.img_tensors[idx]
lab_tensor = self.lab_tensors[idx]
# Decide whether to apply each random transformation
random_transforms = [random.random() < 0.5 for i in range(6)]
# Apply vertical flip
if random_transforms[0]:
img_tensor, lab_tensor = T_F.vflip(img_tensor), T_F.vflip(lab_tensor)
# Apply horizontal flip
if random_transforms[1]:
img_tensor, lab_tensor = T_F.hflip(img_tensor), T_F.hflip(lab_tensor)
# Apply Gaussian blur
if random_transforms[2]:
img_tensor = gaussian_blur_3d(img_tensor, random.randint(1, 2) * 2 + 1)
# Apply padding and cropping
if random_transforms[3]:
# Randomly generate padding sizes
left_pad_size = random.randint(2, 64)
right_pad_size = random.randint(2, 64)
up_pad_size = random.randint(2, 64)
down_pad_size = random.randint(2, 64)
img_tensor = img_tensor[:, up_pad_size:-down_pad_size, left_pad_size:-right_pad_size]
lab_tensor = lab_tensor[:, up_pad_size:-down_pad_size, left_pad_size:-right_pad_size]
padding = (left_pad_size, right_pad_size,
up_pad_size, down_pad_size,
0, 0)
img_tensor = F.pad(img_tensor, padding, mode="constant")
lab_tensor = F.pad(lab_tensor, padding, mode="constant")
# Apply rotations
if random_transforms[4]:
rotation_angle = random.uniform(-90, 90)
img_tensor = T_F.rotate(img_tensor, rotation_angle)
lab_tensor = T_F.rotate(lab_tensor, rotation_angle)
# Apply contrast adjustments
if random_transforms[5]:
img_tensor = adjust_contrast_3d(img_tensor)
img_tensor = img_tensor[None, :].to(torch.float16)
return img_tensor, lab_tensor
The model itself and training process:
(I know it’s handled by pytorch lightning but just in case it’s indeed a bug at pytorch end)
class HalfNet(nn.Module):
def __init__(self):
super(HalfNet, self).__init__()
channel_base = 18
self.inc = ModuleComponents.DoubleConv3D(1, channel_base, ghost=False, kernel_size=(1, 3, 3))
self.down1 = ModuleComponents.Down3D(channel_base, channel_base, ghost=False, kernel_size=(1, 3, 3))
self.merge1 = ModuleComponents.Merge3D(2)
self.down2 = ModuleComponents.Down3D(channel_base, channel_base, ghost=False, kernel_size=(1, 3, 3))
self.merge2 = ModuleComponents.Merge3D(4)
self.down3 = ModuleComponents.Down3D(channel_base, channel_base, ghost=False, kernel_size=(1, 3, 3))
self.merge3 = ModuleComponents.Merge3D(8)
self.down4 = ModuleComponents.Down3D(channel_base, channel_base, ghost=False, kernel_size=(1, 3, 3))
self.merge4 = ModuleComponents.Merge3D(16)
self.down5 = ModuleComponents.Down3D(channel_base, channel_base, ghost=False, kernel_size=(1, 3, 3))
self.merge5 = ModuleComponents.Merge3D(32)
self.z_work = ModuleComponents.DoubleConv3D(channel_base, channel_base, ghost=False, kernel_size=(3, 1, 1))
self.outc = ModuleComponents.OutConv3D(channel_base, 2)
def forward(self, x):
x = self.inc(x)
x2 = self.down1(x)
x = self.merge1(x, x2)
x2 = self.down2(x2)
x = self.merge2(x, x2)
x2 = self.down3(x2)
x = self.merge3(x, x2)
x2 = self.down4(x2)
x = self.merge4(x, x2)
x2 = self.down5(x2)
x = self.merge5(x, x2)
x = self.z_work(x)
x = self.outc(x)
return x
class HalfNetPL(pl.LightningModule):
def __init__(self, learning_rate=0.001):
super(HalfNetPL, self).__init__()
self.model = HalfNet()
self.learning_rate = learning_rate
#self.automatic_optimization = False
def forward(self, image):
return self.model(image)
def training_step(self, batch, batch_idx):
#loss = self._step(batch, batch_idx)
#self.log("train_loss", loss, on_step=False, on_epoch=True, prog_bar=True, logger=True)
return {'loss': self._step(batch, batch_idx)}
def validation_step(self, batch, batch_idx):
loss = self._step(batch, batch_idx)
self.log("val_loss", loss, on_step=False, on_epoch=True, prog_bar=False, logger=False)
return {'val_loss': loss}
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=self.learning_rate)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=30,
threshold=0.0001, threshold_mode='rel',
cooldown=0, min_lr=0.00025, verbose=True)
return {"optimizer": optimizer,
"lr_scheduler": {"scheduler": scheduler, "monitor": "val_loss"},}
def lr_scheduler_step(self, scheduler, optimizer_idx, metric):
if metric is None:
scheduler.step()
else:
scheduler.step(metric)
def predict_step(self, batch, batch_idx: int, dataloader_idx: int = 0):
x = batch
return torch.argmax(self(x), dim=1)
def validation_epoch_end(self, outputs):
avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
self.logger.experiment.add_scalar("Loss/Val", avg_loss, self.current_epoch)
self.val_loss = avg_loss
def training_epoch_end(self, outputs):
#if(self.current_epoch==0):
#sampleImg = torch.rand((1,1,5,128,128))
#self.logger.experiment.add_graph(HalfNet(), sampleImg)
avg_loss = torch.stack([x['loss'] for x in outputs]).mean()
self.logger.experiment.add_scalar("Loss/Train", avg_loss, self.current_epoch)
def test_step(self, batch, batch_idx):
loss = self._step(batch, batch_idx)
self.log("test_loss", loss, on_step=False, on_epoch=True, prog_bar=True, logger=True)
return {'test_loss': loss}
def _step(self, batch, batch_idx):
x, y = batch
y_hat = self.forward(x)
#weight = torch.tensor(data=(1, 1), device=self.device)
#weight = weight.to(torch.float)
loss = F.cross_entropy(input=y_hat, target=y)
return loss
if __name__ == "__main__":
train_dataset = DataComponents.Train_Dataset('datasets/train/img',
'datasets/train/lab',)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=2, shuffle=True, num_workers=2, pin_memory=False)
# Setting up training parameters
torch.set_float32_matmul_precision('medium')
trainer = pl.Trainer(max_epochs=200, log_every_n_steps=1, logger=logger,
accelerator="gpu", enable_checkpointing=False,
precision=16, auto_lr_find=True, gradient_clip_val=0.5,)
model = HalfNetPL()
# Train the model
trainer.fit(model,
train_dataloaders=train_loader)
Thank you.