Hello everyone, let me explain you a little background of my project and then I will tell you what problem I am facing so you get a clear picture of my problem.
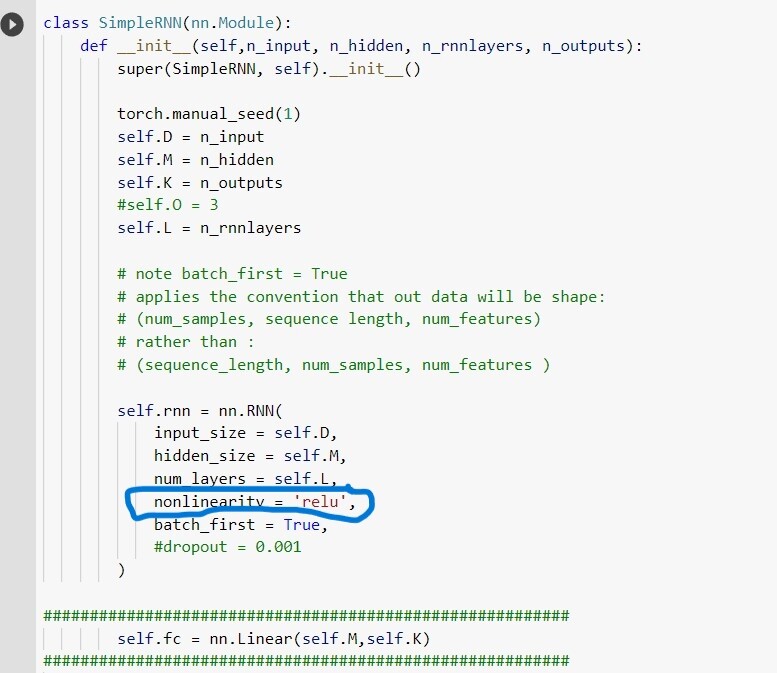
so using pytroch.nn.RNN I trained neural network with 4 input neuron, 2 hidden layers , each have 8 neurons and 2 output neurons. so I trained my RNN model and I choose relu in 'nonlinearity ’ option and everything is fine there , my results are also ok. here is the picture of my model.
(its just half code because I am not allowed to post 2 pictures)
now as per my project requirements, I had to make same RNN structure from scratch using trained weights of the above-inbuilt model and I did that but my results are not matching when I apply relu activation function as ( relu(x) = max(0,x) ). but when I use ‘Tanh’ activation in inbuilt model and use that trained weights, then my model which I made from scratch is giving similar results as inbuilt model. i know there are several types of ‘relu’ activation functions and I tried a lot to find out what relu is exactly used by inbuilt model but I couldn’t find any answer so please please anyone can tell me exactly what relu RNN module is using so that I can also use the same and get results. It will be great help as I am in last semester of my masters and I am stuck in relu.
i also gone through it several times and I am not able to run torch._VF.rnn_relu. which is given in source code and I tried my best to make it run but libraries which are mentioned in source code , that I am not able to import in my google colab notebook even after installing all of them in colab.
It’s documented within the source file, https://pytorch.org/docs/stable/_modules/torch/nn/modules/rnn.html#RNN
torch._VF.rnn_relu
can someone please help me in this… thank you in advance
Parameters
...
num_layers – Number of recurrent layers. E.g., setting num_layers=2 would mean stacking two RNNs together to form a stacked RNN, with the second RNN taking in outputs of the first RNN and computing the final results. Default: 1
nonlinearity – The non-linearity to use. Can be either 'tanh' or 'relu'. Default: 'tanh'
...
As per the documentaton, the default non linearity in the RNN module is tanh. This might be the reason why your model performs well with inbuilt model with tanh
Both tanh and relu have their own advantages and disadvantages, so at a general level you will have to understand your data and model and apply accordingly
i think you didn’t understand my problem. activation functions mathematics we all know right. it doesn’t matter weather I use relu or tanh as activation function when I m using trained weights by Pytorch RNN module and that is giving fine results then why m self coded RNN is not giving similar results as pytroch module. and that is only when I use relu as a activation function , when I use tanh in pytorch module and match the ans with my self coded RNN both are matching that means there is no problem in my codes. i just want to know what type of relu exactly they used while building RNN.
Before you compare the results, you have to ensure that both are using the same random seed
Also, when you see that your results are not matching with the inbuilt function’s output, are you comparing the output of self.rnn or are you checking the output after the self.fc ( fully connected layers )
The reason is ask this is because for RNN we have just two activations inbuilt ( TANH and RELU ) but for a general layer there are lots of activation functions like LEAKYRELU etc
Can you share the forward code of the above module, so that we can help further
can i share my codes which i made from scratch because your answers are somewhere out of the point until unless you see both the things.may be after that I can get proper solution.
I looked where this rabbit hole leads and it is way deeper, up to libcudnn.so
maybe someone from pytorch team will help here, but I think that It is much easier to trace where your calculations divert. For example, when you run single block with relu, have you checked that all positive values of result tensors match? Since, you know, ReLU only zeroing up negative values, so your positive values should match.