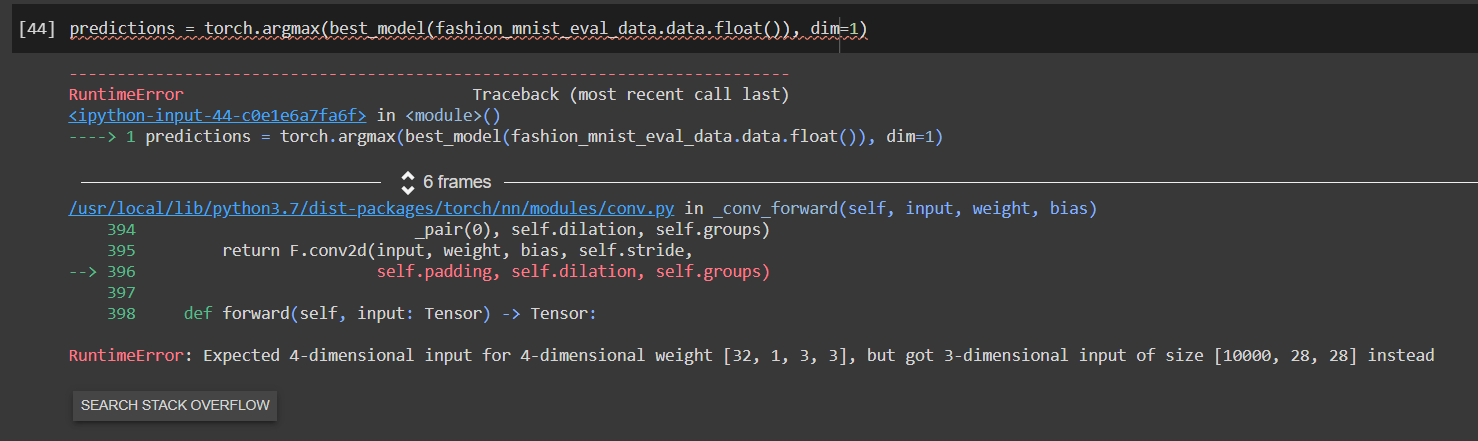
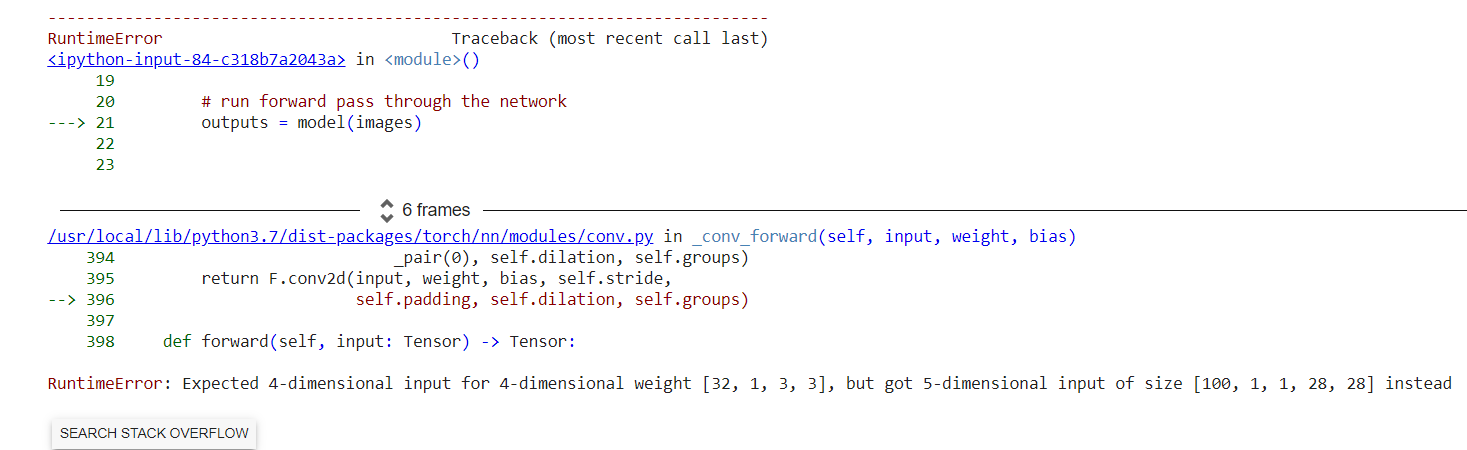
You’ll need to reshape/unsqueeze your inputs as [10000, 1, 28, 28]. You need to this this because the network expects inputs of shape [_, channel, height, width].
You could do it in your forward function as images=images.unsqueeze(dim=1). However, it would be better if you include this step in your data preprocessing pipeline.
def forward(self, images):
images=images.unsqueeze(dim=1)
x = self.layer_1(images)
x = self.layer_2(x)
x = x.view(x.size(0), -1)
x = self.linear1(x)
x = self.drop(x)
x = self.linear2(x)
x = self.linear3(x)
# define layer 3 forward pass
# x = self.logsoftmax(self.linear3(x))
# return forward pass result
return x
But it still leads to an issue here:
init collection of training epoch losses
train_epoch_losses =
set the model in training mode
model.train()
train the MNISTNet model
for epoch in range(num_epochs):
# init collection of mini-batch losses
train_mini_batch_losses = []
# iterate over all-mini batches
for i, (images, labels) in enumerate(fashion_mnist_train_dataloader):
# push mini-batch data to computation device
images = images.to(device)
labels = labels.to(device)
# run forward pass through the network
outputs = model(images)
# reset graph gradients
model.zero_grad()
# determine classification loss
loss = nll_loss(outputs, labels)
# run backward pass
loss.backward()
# update network paramaters
optimizer.step()
# collect mini-batch reconstruction loss
train_mini_batch_losses.append(loss.data.item())
# determine mean min-batch loss of epoch
train_epoch_loss = np.mean(train_mini_batch_losses)
# print epoch loss
now = datetime.utcnow().strftime("%Y%m%d-%H:%M:%S")
print('[LOG {}] epoch: {} train-loss: {}'.format(str(now), str(epoch), str(train_epoch_loss)))
# set filename of actual model
model_name = 'fashion_mnist_model_epoch_{}.pth'.format(str(epoch))
# save current model to GDrive models directory
torch.save(model.state_dict(), os.path.join(models_directory, model_name))
# determine mean min-batch loss of epoch
train_epoch_losses.append(train_epoch_loss)