I’d like a fast serialization for a tensor. Right now, I’m using
x = torch.Tensor(...)
serialized = pickle.dumps(x)
The tensor is not guaranteed to live on the CPU and I want to preserve CPU–GPU bandwidth, meaning I can not use
x.numpy().tobytes()
Is there a fast serialization method for torch Tensors?
Notes on research I’ve done so far:
the source for torch.serialization and it relies on pickle.dumps (plus it seems oriented towards files, not speed).
blosc has compress_ptrx.data_ptr
I’ve looked at pyarrow too, but decided to ask here first
2 Likes
stsievert
December 19, 2017, 7:55pm
2
smth
December 19, 2017, 9:49pm
3
pytorch defines a custom pickler, so pickle.dump with the custom pickler is actually very fast (we go into C for serializing the storage)
stsievert
December 19, 2017, 11:15pm
4
Right, I should clarify.
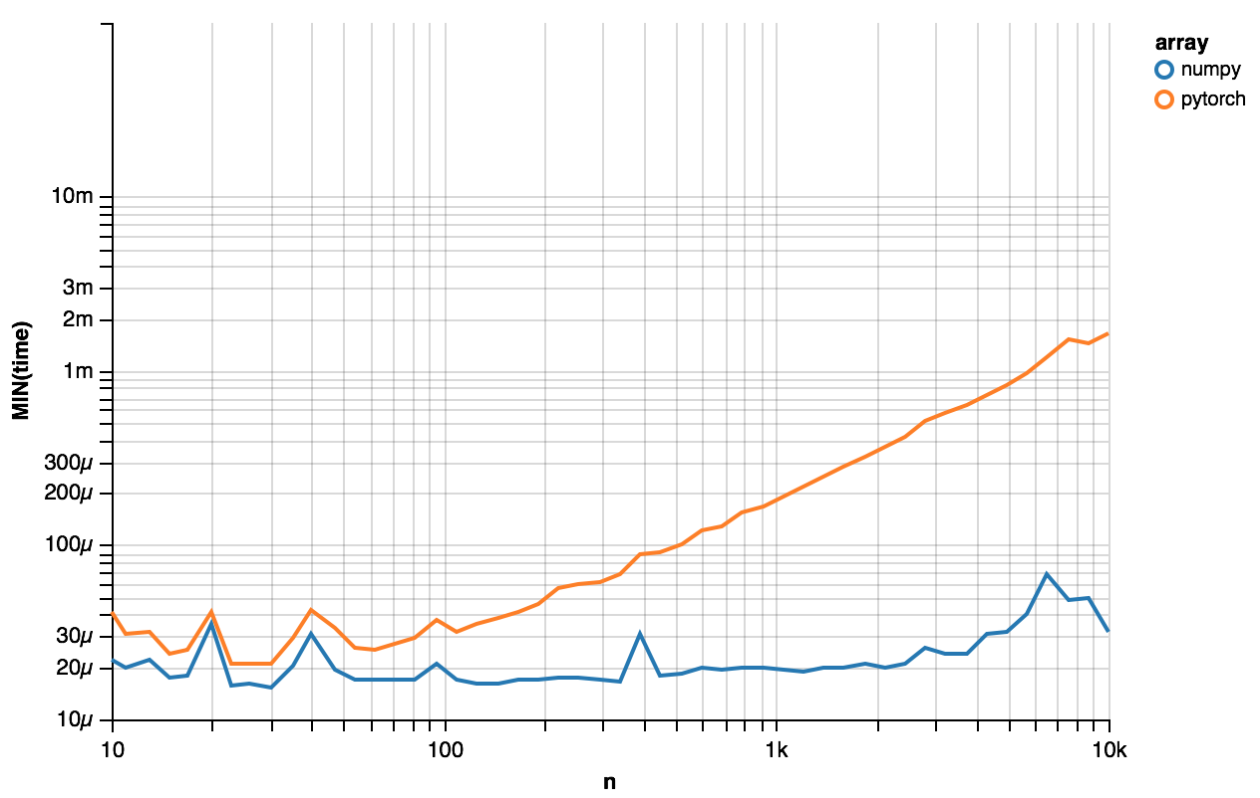
I’m comparing with NumPy serialization. The picture below times serialization for NumPy and PyTorch with pickle.dumps on a Macbook Pro 2015.
The core of my code was
def stat(x, serialize=pickle.dumps):
start = time.time()
msg = serialize(x)
return {'time': time.time() - start, 'bytes': len(msg)}
# ... other functions, for-loops, etc
x = np.random.randn(n).astype('float32')
y = torch.Tensor(x)
This is with torch.__version__ == 0.3.0.post4.
mrshenli
April 18, 2019, 4:01pm
5
@stsievert Is the fix in #9184 sufficient?
Yup. Well, I think so. That PR was actually motivated by some of the work I did over the summer. I wouldn’t be surprised if the NumPy and PyTorch timings are equally fast now (but I’d like to see the graph).
Here’s the same graph with PyTorch 1.0.0 and NumPy 1.16.2:
2 Likes
It would be super nice to add pyarrow here.