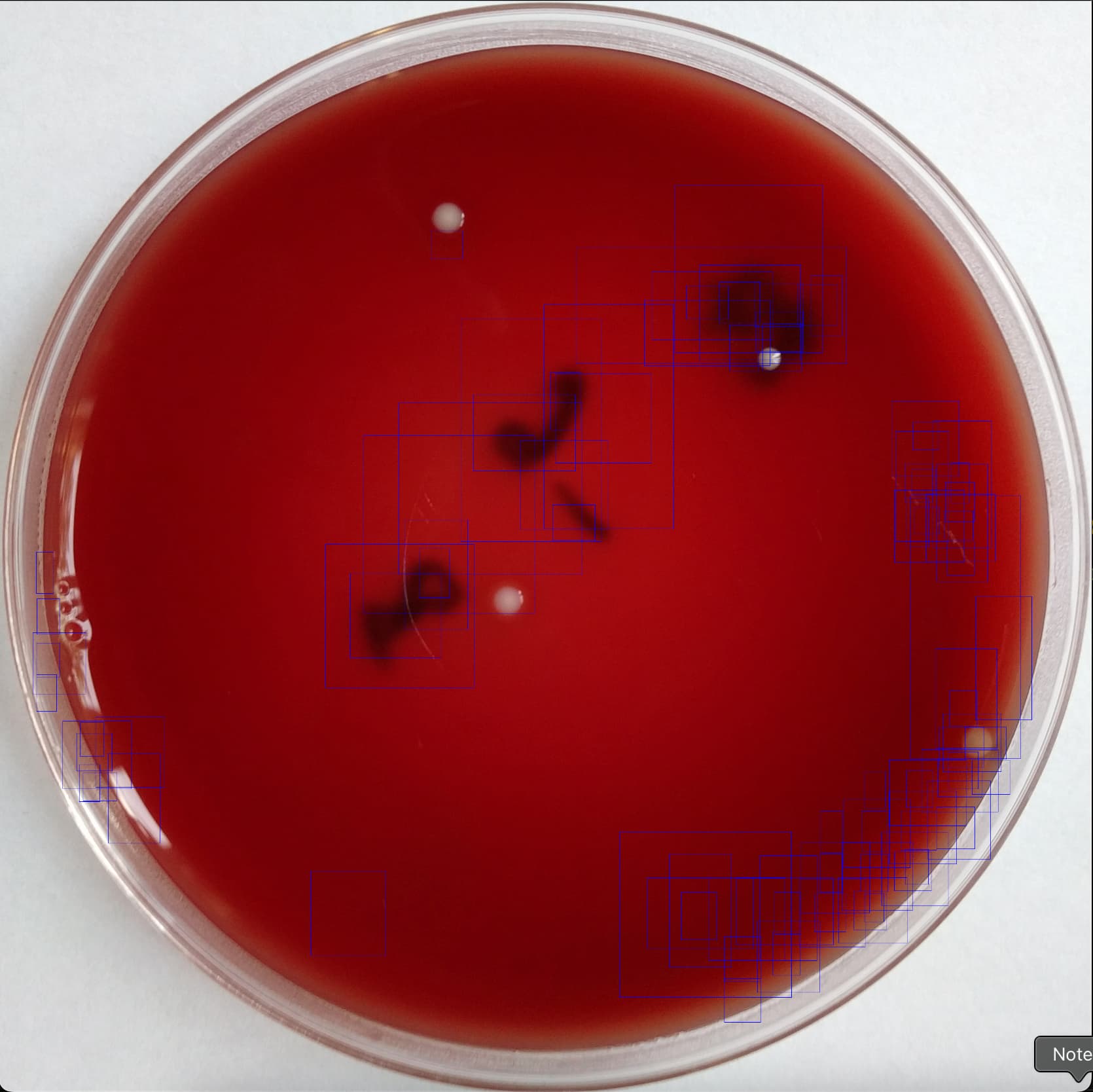
Hi, I’m having trouble creating a Faster R-CNN around this dataset: Annotated dataset for deep-learning-based bacterial colony detection
It’s already in COCO labeled format, and I attempted to create an R-CNN using the following code (granted this is my first time with the architecture). However, the test image I feed into the model at the end always has MANY more bounding boxes than there are objects to detect. These boxes just don’t make sense either. The original paper ran the model at 100 epochs, so perhaps that is my issue, however, am I wrong to believe that the model should still somewhat accurately predict with only 10? Also, if I was to run 100 epochs, would you have any suggestions on how to feasibly run such a task. Since I’m using an M4 Pro Macbook, I don’t believe my hardware could really handle this much computation. Additionally, I would love to hear any feedback on ways that I could make my implementation faster, more accurate, or just in general more organized. Thank you!
model.py
import torch
from torch.utils.data import DataLoader
import torchvision
from torchvision.models.detection import fasterrcnn_resnet50_fpn
from torchvision.datasets import ImageFolder
from torchvision import transforms
import torchvision.transforms as T
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
from datatset import CFUDataset
from dataset2 import CFUDataset2
import cv2
from PIL import Image
def test_accuracy(net, device="cpu"):
correct = 0
total = 0
with torch.no_grad():
for images, targets in valid_loader:
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
loss_dict = model(images, targets)
print(loss_dict)
model = torchvision.models.detection.fasterrcnn_mobilenet_v3_large_fpn(weights="FasterRCNN_MobileNet_V3_Large_FPN_Weights.DEFAULT")
num_classes = 2
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
transform = T.Compose([
T.ToTensor(),
])
dataset = CFUDataset(root_dir="CFU_Dataset", annotations_json="CFU_Dataset/annot_COCO.json", transforms=transform)
indices = torch.randperm(len(dataset)).tolist()
train_dataset = torch.utils.data.Subset(dataset, indices[:-50])
valid_dataset = torch.utils.data.Subset(dataset, indices[-50:])
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True,
collate_fn=lambda x: tuple(zip(*x)))
valid_loader = DataLoader(valid_dataset, batch_size=8, shuffle=False,
collate_fn=lambda x: tuple(zip(*x)))
device = torch.device('cpu')
if torch.cuda.is_available():
device = torch.device('cuda')
model.to(device)
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.00001, momentum=0.9,
weight_decay=0.0005)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=3,
gamma=0.1)
num_epochs = 5
for epoch in range(num_epochs):
model.train()
train_loss = 0.0
total = len(train_loader)
count = 1
for images, targets in train_loader:
print(f"{count/total*100:.1f} %, Loss: {train_loss / count}",end="\r")
count += 1
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
optimizer.zero_grad()
loss_dict = model(images, targets)
losses = sum(loss for loss in loss_dict.values())
losses.backward()
optimizer.step()
train_loss += losses.item()
lr_scheduler.step()
print(f'Epoch: {epoch + 1}, Loss: {train_loss / len(train_loader)}')
print("Training complete!")
model.eval()
import cv2
import torchvision.transforms as T
import torch
transform = T.Compose([
T.ToTensor(), # Convert PIL Image to Tensor
])
img = Image.open('CFU_Dataset/sp01_img02.jpg')
img = transform(img) # Apply the transformation
img = img.float() # Ensure the tensor is float32
with torch.no_grad():
prediction = model([img])
img = cv2.imread('CFU_Dataset/sp01_img02.jpg')
for i in range(len(prediction[0]['boxes'])):
x1, x2, x3, x4 = map(int, prediction[0]['boxes'][i].tolist())
print(prediction[0]['scores'][i])
image = cv2.rectangle(img, (x1, x2), (x3, x4), (255, 0, 0), 1)
cv2.imshow('CFU_Dataset/sp01_img02.jpg', image)
cv2.waitKey()
datatset.py
import torch
import json
import os
from PIL import Image
class CFUDataset(torch.utils.data.Dataset):
def __init__(self, annotations_json, root_dir, transforms):
file = open(annotations_json,)
self.annotations = json.load(file)
self.root_dir = root_dir
self.transforms = transforms
def __getitem__(self, idx):
img_path = os.path.join(self.root_dir, self.annotations['images'][idx].get('file_name'))
img_id = self.annotations['images'][idx].get('id')
img = Image.open(img_path)
boxes_array = []
for annotation in self.annotations['annotations']:
if annotation.get('image_id') == img_id:
bbox = annotation.get('bbox')
bbox = [bbox[0], bbox[1], bbox[0] + bbox[2], bbox[1] + bbox[3]]
if bbox[2] > bbox[0] and bbox[3] > bbox[1]:
boxes_array.append(bbox)
boxes = torch.FloatTensor(list(boxes_array))
labels = torch.tensor([1] * len(boxes_array), dtype=torch.int64)
target = {}
target["boxes"] = boxes.clone().detach()
target["labels"] = labels.clone().detach()
if self.transforms is not None:
img = self.transforms(img)
return img, target
def __len__(self):
return len(self.annotations['images'])
Example output (white colonies are the objects, only one class):