Hi,
I’ve tried the following code but its not improving the maP and recall.
import numpy as np
from torchmetrics.detection import IntersectionOverUnion
from torchmetrics.detection import MeanAveragePrecision
import math
class CocoDNN(L.LightningModule):
def __init__(self):
super().__init__()
self.model = models.detection.fasterrcnn_mobilenet_v3_large_fpn(weights="DEFAULT")
self.metric = MeanAveragePrecision(iou_type="bbox",average="macro",class_metrics = True, iou_thresholds=[0.5, 0.75],extended_summary=True, backend="faster_coco_eval")
def forward(self, images, targets=None):
return self.model(images, targets)
def training_step(self, batch, batch_idx):
imgs, annot = batch
batch_losses = []
for img_b, annot_b in zip(imgs, annot):
#print(len(img_b), len(annot_b))
if len(img_b) == 0:
continue
loss_dict = self.model(img_b, annot_b)
losses = sum(loss for loss in loss_dict.values())
#print(losses)
batch_losses.append(losses)
batch_mean = torch.mean(torch.stack(batch_losses))
self.log('train_loss', batch_mean, on_step=True, on_epoch=True, prog_bar=True, logger=True)
return batch_mean
def validation_step(self, batch, batch_idx):
imgs, annot = batch
targets ,preds = [], []
for img_b, annot_b in zip(imgs, annot):
if len(img_b) == 0:
continue
if len(annot_b)> 1:
targets.extend(annot_b)
else:
targets.append(annot_b[0])
loss_dict = self.model(img_b, annot_b)
if len(loss_dict)> 1:
preds.extend(loss_dict)
else:
preds.append(loss_dict[0])
self.metric.update(preds, targets)
map_results = self.metric.compute()
self.log('precision', map_results['precision'].mean().float().item(),on_step=True, on_epoch=True, prog_bar=True, logger=True)
self.log('recall', map_results['recall'].mean().float().item(),on_step=True, on_epoch=True, prog_bar=True, logger=True)
self.log('map_50', map_results['map_50'].float().item(),on_step=True, on_epoch=True, prog_bar=True, logger=True)
self.log('map_75', map_results['map_75'].float().item(),on_step=True, on_epoch=True, prog_bar=True, logger=True)
return map_results['map_75']
def configure_optimizers(self):
return optim.SGD(self.parameters(), lr=0.001, momentum=0.9, weight_decay=0.0005)
dnn = CocoDNN()
#version=1,
logger = TensorBoardLogger(save_dir=os.getcwd(), name="runs")
#limit_train_batches=100,
trainer = L.Trainer(max_epochs=100,accelerator='gpu',logger=logger,log_every_n_steps=50)
trainer.fit(model=dnn, train_dataloaders=TRAIN_DATALOADER,val_dataloaders=VAL_DATALOADER)
here are the tensorboard details. Image size if 512x512 and its binary class problem to identify the defected BB of images
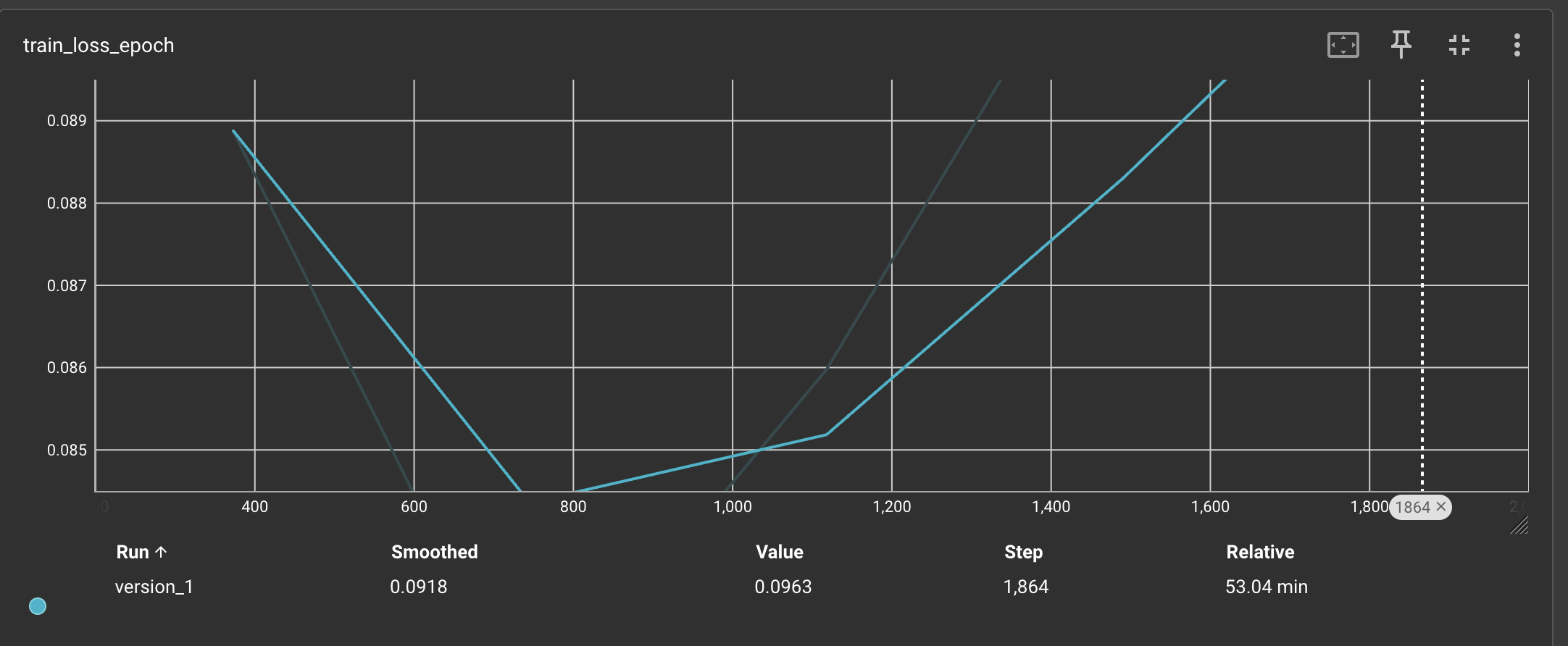
Recall and Precision is negative so maP is very low. 5 epoch details are
train_loss_step=0.0949, precision_step=-0.916, recall_step=-0.908, map_50_step=0.0208, map_75_step=0.00272, precision_epoch=-0.916, recall_epoch=-0.908, map_50_epoch=0.0201, map_75_epoch=0.00269, train_loss_epoch=0.0963]