hi,
is it possible to feed every time step initial thought vector to predict output instead of hidden input in LSTM cell? or concatenated with hidden input. this is for image captioning (refer to image)
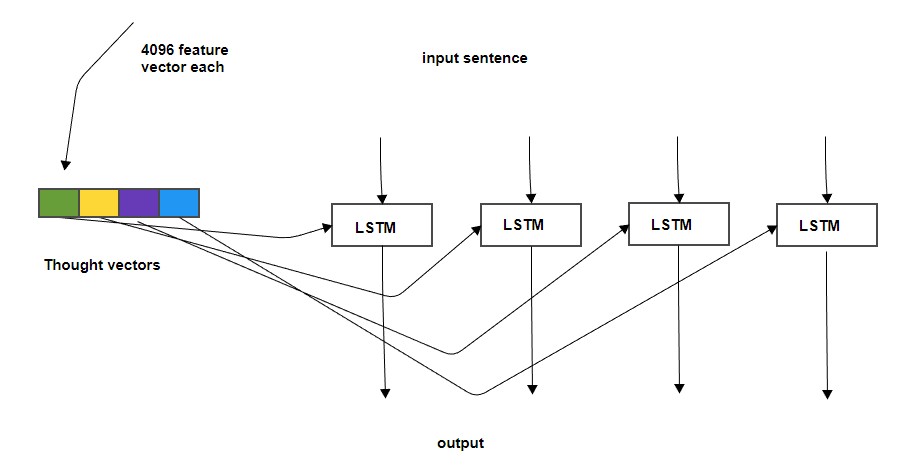
I think it is possible. During training using the LSTM cell (which is in a for loop), just re-fed the same vector instead of the hidden that the model returns as in here.
any sample code pls…
I mean when you do ht, (hn, cn) = lstm(input, (h0, c0)) and if you do batch_first=True then output is all the hidden states and it is of dimensions B X L X D (with padding). So, one batch for example is ht[0, : , :] and this is the full sequence of hidden states. ht[0, 0, :] is the first hidden sate in batch 1, ht[0, 1, :] is the second in batch 1, etc. If you have another vector kt then you can do something like zt = torch.concat((ht, kt), axis=-1) to make this concatenated so that each hidden state in each batch is appended a vector so the dimension of the above is B X L X (D + D’) where D’ is the dimension of each of your kt batch vectors. Then, you can just apply wt = nn.Linear(zt) to go to a new dimension B X L X D’’ (D’’ is your wanted output dimension) and then you can do a softmax on the last output nn.Softmax(axis=2)(wt) to finally get the outputs per timestep of lstm … Basically, you are adding something to each time step of each batch, hidden states you had in the LSTM …