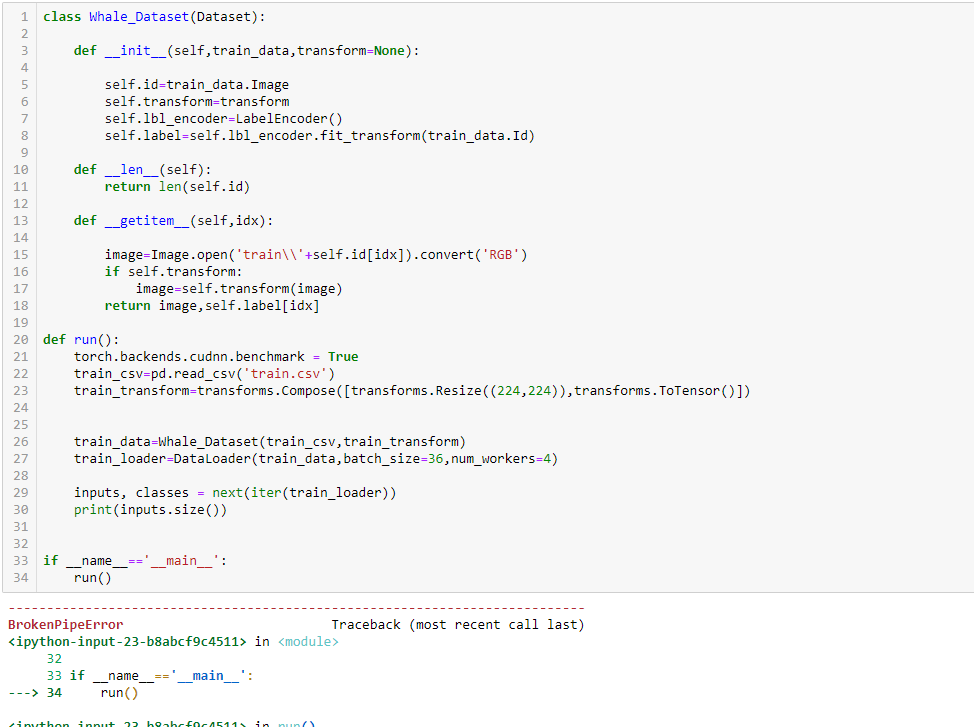
I ran into a rather curious problem while trying to implement this semi-supervised representation learning algorithm
(tl;dr Pretrain a CNN by letting it solve jigsaw puzzles. Each image gets cut into nine tiles. These tiles are permutated with a precalculated permutation and the net has to predict the index in the permutation set)
I am using a custom Permutator object to hold the permutations, which I load from a file.
This object is given to my wrapper class around torchvision.datasets.ImageFolder().
When I set num_workers > 0 in torch.utils.data.DataLoader(), the whole script gets executed multiple times before each epoch.
Here is some pseudo-code of my setup:
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset
from torchvision import datasets, transforms
from pathlib import Path
import permutation
import jigsaw_model
torch.backends.cudnn.benchmark = True
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Define hyperparameters
image_size = (99, 99)
batch_size = 256
n = 3
lr = 10e-3
n_epochs = 100
# Create custom permutation object
# This object holds a list of 100 permutations and can select one at random
permutator = permutation.Permutation(filename=Path("data", "permutations_max_100.csv"))
print("Permutator created.")
# Training transforms
transforms_train = transforms.Compose([
... # Normalize the image and cut it into n*n puzzle tiles
])
# Image files
images_train = datasets.ImageFolder(root="my_path/to/images", transform=None)
# This is just a wrapper on torchvision.datasets.ImageFolder(). It loads an image, cuts it into n*n puzzle tiles
# and permutates the tiles with a permutation obtained from the permutator object
dataset_train = jigsaw_model.JigsawTileDataset(dataset=images_train, transform=transforms_train, n=n,
permutator=permutator)
# If I set num_workers > 0 here, all the above code is executed multiple times
num_workers = 0
loader_train = torch.utils.data.DataLoader(dataset_train, num_workers=num_workers, shuffle=True, pin_memory=True,
batch_size=batch_size)
# Define the model
model = ...
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
if __name__ == '__main__':
for epoch in range(n_epochs):
train(...)
validate(...)
A minimal working example can be found here.
How often the code is executed can be tracked by the output print("Permutator created.").
It seems to be num_workers+1, which makes sense, since it’s one for the base process and one for each worker.
Nevertheless I am puzzled by this behaviour, since I want to avoid multiple creation of the Permutator object before each epoch, but still I wish to use multiple workers for speed considerations.
Any help on this would be very much appreciated 
I am using the following setup:
Pytorch 0.4
Python 3.6
Windows 7
Wether I run the code from Pycharm or the Anaconda console, the same behaviour is observed.