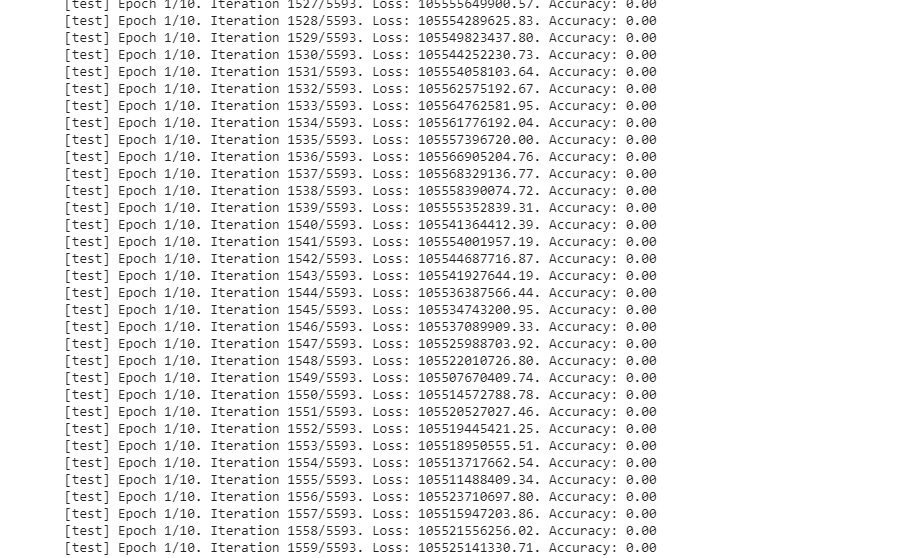
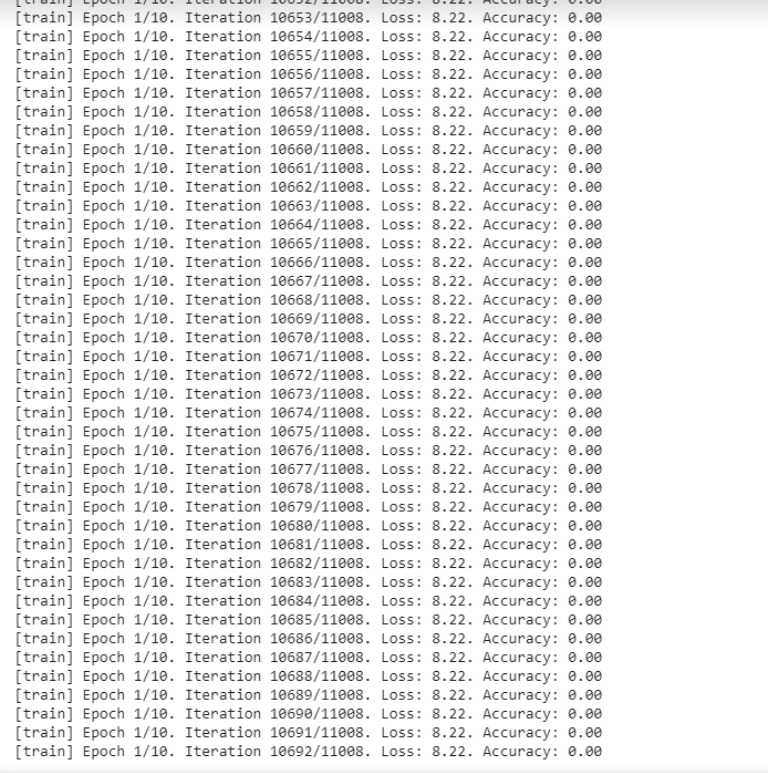
Yes the test loss is huge that’s why I stopped the training, I didn’t modify anything in the code, and according to the directory, it must work. If you have any changes to make please tell me. thanks.
PS: it took 3h to run 1 epoch.
I just modified the path of the dataset.
from dataset import torch, os, LocalDataset, transforms, np, get_class, num_classes, preprocessing, Image, m, s
from config import *
from torch import nn
from torch.optim import SGD
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision.models import resnet
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import f1_score
from matplotlib import pyplot as plt
from numpy import unravel_index
import gc
import argparse
parser = argparse.ArgumentParser(description='car model recognition')
parser.add_argument("-i", "--input", action="store", dest="inp", help="Take a sample image and classify it", type=str)
parser.add_argument("-t", "--train", action="store_true", help="Run the training of the model")
parser.add_argument("-p", "--preprocess", action="store_true", help="Update the train and test csv files with the new images in dataset, used this if you added new images in dataset")
args = parser.parse_args()
if args.preprocess:
print ("Preprocessing..")
preprocessing()
print ("Preprocessing finished!")
cuda_available = torch.cuda.is_available()
# directory results
if not os.path.exists(RESULTS_PATH):
os.makedirs(RESULTS_PATH)
# Load dataset
mean=m
std_dev=s
transform = transforms.Compose([transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize(mean, std_dev)])
training_set = LocalDataset(IMAGES_PATH, TRAINING_PATH, transform=transform)
validation_set = LocalDataset(IMAGES_PATH, VALIDATION_PATH, transform=transform)
training_set_loader = DataLoader(dataset=training_set, batch_size=BATCH_SIZE, num_workers=THREADS, shuffle=True)
validation_set_loader = DataLoader(dataset=validation_set, batch_size=BATCH_SIZE, num_workers=THREADS, shuffle=False)
def train_model(model_name, model, lr=LEARNING_RATE, epochs=EPOCHS, momentum=MOMENTUM, weight_decay=0, train_loader=training_set_loader, test_loader=validation_set_loader):
if not os.path.exists(RESULTS_PATH + "/" + model_name):
os.makedirs(RESULTS_PATH + "/" + model_name)
criterion = nn.CrossEntropyLoss()
optimizer = SGD(model.parameters(), lr, momentum=momentum, weight_decay=weight_decay)
loaders = {'train':train_loader, 'test':test_loader}
losses = {'train':[], 'test':[]}
accuracies = {'train':[], 'test':[]}
#testing variables
y_testing = []
preds = []
if USE_CUDA and cuda_available:
model=model.cuda()
for e in range(epochs):
for mode in ['train', 'test']:
if mode=='train':
model.train()
else:
model.eval()
epoch_loss = 0
epoch_acc = 0
samples = 0
try:
for i, batch in enumerate(loaders[mode]):
# convert tensor to variable
x=Variable(batch['image'], requires_grad=(mode=='train'))
y=Variable(batch['label'])
if USE_CUDA and cuda_available:
x = x.cuda()
y = y.cuda()
output = model(x)
l = criterion(output, y) # loss
if mode=='train':
l.backward()
optimizer.step()
optimizer.zero_grad()
else:
y_testing.extend(y.data.tolist())
preds.extend(output.max(1)[1].tolist())
if USE_CUDA and cuda_available:
acc = accuracy_score(y.data.cuda().cpu().numpy(), output.max(1)[1].cuda().cpu().numpy())
else:
acc = accuracy_score(y.data, output.max(1)[1])
epoch_loss += l.data.item()*x.shape[0] # l.data[0]
epoch_acc += acc*x.shape[0]
samples += x.shape[0]
print ("\r[%s] Epoch %d/%d. Iteration %d/%d. Loss: %0.2f. Accuracy: %0.2f" % \
(mode, e+1, epochs, i, len(loaders[mode]), epoch_loss/samples, epoch_acc/samples))
if DEBUG and i == 2:
break
except Exception as err:
print ("\n\n######### ERROR #######")
print (str(err))
print ("\n\n######### batch #######")
print (batch['img_name'])
print ("\n\n")
epoch_loss /= samples
epoch_acc /= samples
losses[mode].append(epoch_loss)
accuracies[mode].append(epoch_acc)
print ("\r[%s] Epoch %d/%d. Iteration %d/%d. Loss: %0.2f. Accuracy: %0.2f" % \
(mode, e+1, epochs, i, len(loaders[mode]), epoch_loss, epoch_acc))
torch.save(model.state_dict(), str(RESULTS_PATH) + "/" + str(model_name) + "/" + str(model_name) + ".pt")
return model, (losses, accuracies), y_testing, preds
def test_model(model_name, model, test_loader = validation_set_loader):
model.load_state_dict(torch.load(str(RESULTS_PATH) + "/" + str(model_name) + "/" + str(model_name) + ".pt"))
if USE_CUDA and cuda_available:
model = model.cuda()
model.eval()
preds = []
gts = []
#debug
i = 0
for batch in test_loader:
x = Variable(batch['image'])
if USE_CUDA and cuda_available:
x = x.cuda()
pred = model(x).data.cuda().cpu().numpy().copy()
else:
pred = model(x).data.numpy().copy()
gt = batch['label'].numpy().copy()
preds.append(pred)
gts.append(gt)
# debug
if DEBUG:
if i == 2:
break
else:
i+=1
return np.concatenate(preds), np.concatenate(gts)
def write_stats(model_name, y, predictions, gts, predictions2):
if not os.path.exists(RESULTS_PATH + "/" + model_name):
os.makedirs(RESULTS_PATH + "/" + model_name)
acc = accuracy_score(gts, predictions2.argmax(1))
cm = confusion_matrix(y, predictions)
if DEBUG:
score = "00 F1_SCORE 00"
else:
score = f1_score(y, predictions, average=None)
file = open(str(RESULTS_PATH) + "/" + str(model_name) + "/" + str(model_name) + "_stats.txt", "w+")
file.write ("Accuracy: " + str(acc) + "\n\n")
file.write("Confusion Matrix: \n" + str(cm) + "\n\n")
file.write("F1 Score: \n" + str(score))
file.close()
def plot_logs_classification(model_name, logs):
if not os.path.exists(RESULTS_PATH + "/" + model_name):
os.makedirs(RESULTS_PATH + "/" + model_name)
training_losses, training_accuracies, test_losses, test_accuracies = \
logs[0]['train'], logs[1]['train'], logs[0]['test'], logs[1]['test']
plt.figure(figsize=(18,6))
plt.subplot(121)
plt.plot(training_losses)
plt.plot(test_losses)
plt.legend(['Training Loss','Test Losses'])
plt.grid()
plt.subplot(122)
plt.plot(training_accuracies)
plt.plot(test_accuracies)
plt.legend(['Training Accuracy','Test Accuracy'])
plt.grid()
#plt.show()
plt.savefig(str(RESULTS_PATH) + "/" + str(model_name) + "/" + str(model_name) + "_graph.png")
def train_model_iter(model_name, model, weight_decay=0):
if args.train:
model, loss_acc, y_testing, preds = train_model(model_name=model_name, model=model, weight_decay=weight_decay)
preds_test, gts = test_model(model_name, model=model)
write_stats(model_name, y_testing, preds, gts, preds_test)
plot_logs_classification(model_name, loss_acc)
gc.collect()
classes = {"num_classes": len(num_classes)}
resnet152_model = resnet.resnet152(pretrained=False, **classes)
train_model_iter("resnet152", resnet152_model)
model_name="resnet152"
model=resnet152_model
if args.inp:
print ("input: ", args.inp)
image_path = args.inp
im = Image.open(image_path).convert("RGB")
im = transform(im)
print (str(RESULTS_PATH) + "/" + str(model_name) + "/" + str(model_name) + ".pt")
model.load_state_dict(torch.load(str(RESULTS_PATH) + "/" + str(model_name) + "/" + str(model_name) + ".pt"))
if USE_CUDA and cuda_available:
model = model.cuda()
model.eval()
x = Variable(im.unsqueeze(0))
if USE_CUDA and cuda_available:
x = x.cuda()
pred = model(x).data.cuda().cpu().numpy().copy()
else:
pred = model(x).data.numpy().copy()
print (pred)
idx_max_pred = np.argmax(pred)
idx_classes = idx_max_pred % classes["num_classes"]
print(get_class(idx_classes))