Hi,
I am trying to fine-tune my previously trained model. What I did was load the model using load_state_dict and then I changed the initial learning rate to a smaller value. One thing that confused me is that the initial training loss when conducting fine-tuning is quite high, and the value is quite different from the loss I got in previous training. If they have similar model coefficients, how can they have very different losses? or if I misconducted something?
More details are given here, it is a fully connected MLP model, and the loading is as follows:
if model[tag].fineTuneSwitch == True:
model[tag].load_state_dict(torch.load(model[tag].annModelPath))
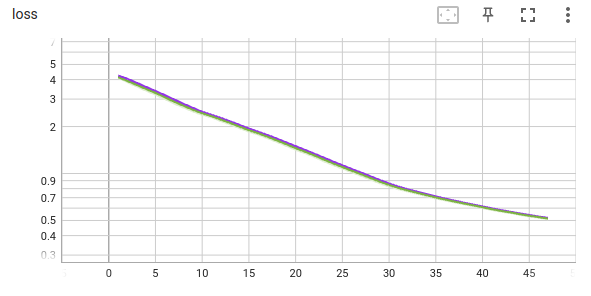
the loss records are attached.
the previous training case (initial learning rate: 1e-3):
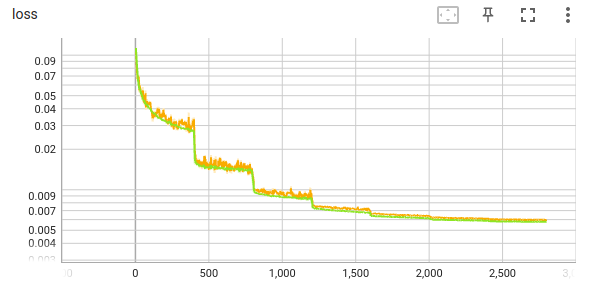
the fine-tuning case (initial learning rate: 4e-6):