Hi there,
do you have a tutorial/guidance on how to finetune provided trained semantic segmentation model of torchvision 0.3 (FCN or DeepLabV3 with Resnet 50 or 101 backbone) on our dataset (transfer learning for semantic segmentation)?
Hi there,
do you have a tutorial/guidance on how to finetune provided trained semantic segmentation model of torchvision 0.3 (FCN or DeepLabV3 with Resnet 50 or 101 backbone) on our dataset (transfer learning for semantic segmentation)?
The general logic should be the same for classification and segmentation use cases, so I would just stick to the Finetuning tutorial.
The main difference would be the output shape (pixel-wise classification in the segmentation use case) and the transformations (make sure to apply the same transformations on the input image and mask, e.g. crop).
This one looks even better for your use case! 
I’ve written a tutorial on how to fine-tune DeepLabv3 for semantic segmentation in PyTorch. The tutorial link is: https://expoundai.wordpress.com/2019/08/30/transfer-learning-for-segmentation-using-deeplabv3-in-pytorch/
The github repo link is: https://github.com/msminhas93/DeepLabv3FineTuning
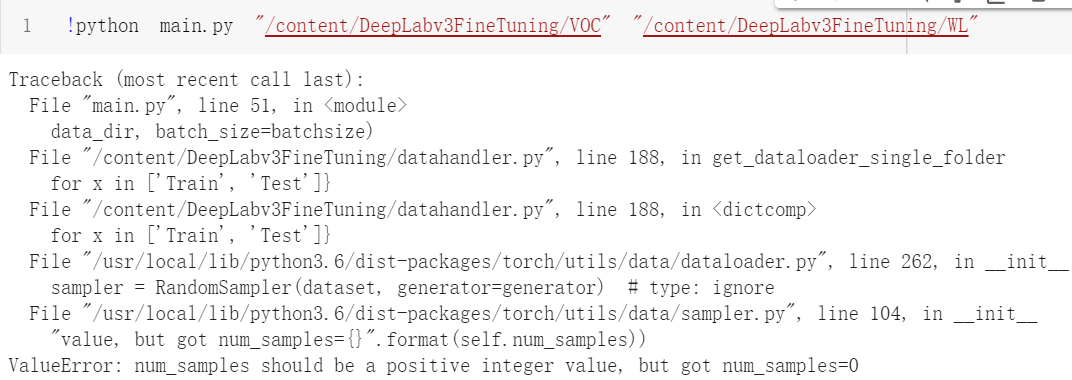
hey your notebook is not loading. giving error. pls share the updated link
Hello,
I am following your link. I have few queries onto this:
I have 3 classes, even though I tried to change the number of out_channels to 3, still model.eval() shows final layer with 21 classes. Please clarify this.
It has batch size 4. I am trying to train it on single image. So when I change batch size to 1, it is throwing an error.
Can you help to decode the result into a mask? I dont know how to do that.
Please help in this regard. Thank you.