Hi everyone,
I was running a resnet50 model loaded to C++ program using torch::jit::load(file_name). After some experiments and profiling, I have seen that the first PyTorch API function call takes a very long time, eg. more than 7 seconds to create a new GPU tensor of size {1,3,224,224} by performing
std::vector<torch::jit::IValue> inputs_vector; inputs_vector.push_back(torch::zeros({1, 3, 224, 224}).to(at::kCUDA));
The long time to create a new CUDA tensor is due to a single very long cudaMalloc call by the program as seen in the NVIDIA visual profiler image below.
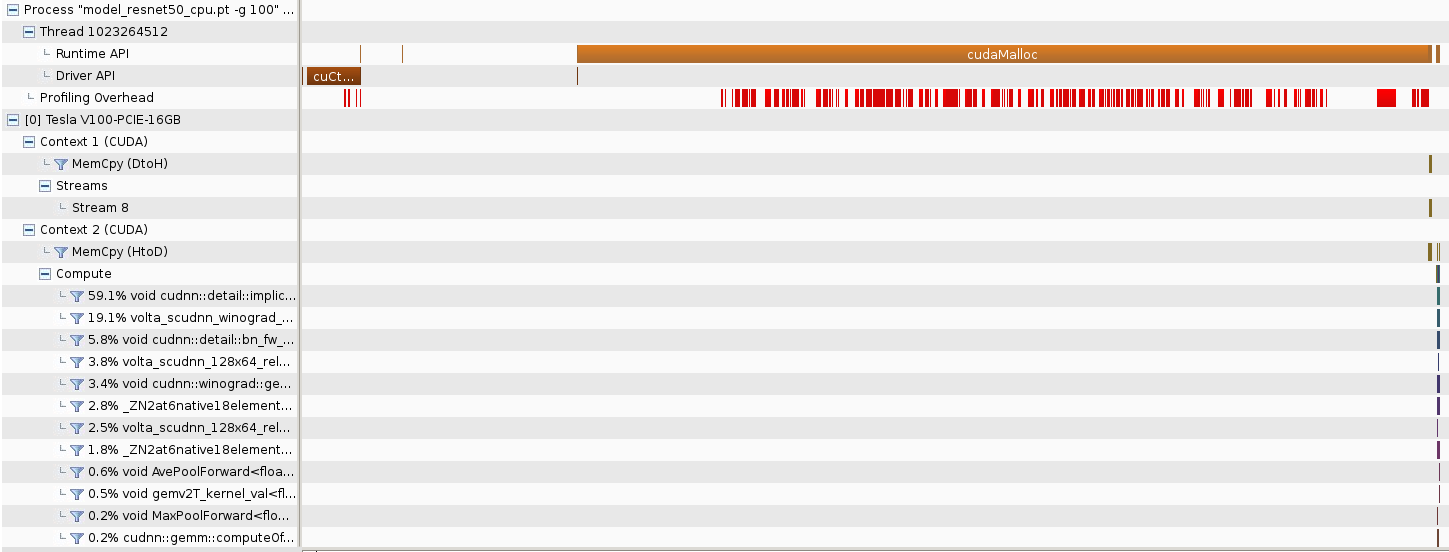
To make sure that it is not a CUDA initialization time, I performed a cudaMalloc of size 1 Gigabyte before I made the tensor using torch API. That initial cudaMalloc only took 431 milliseconds.
What could be the cause of first cudaMalloc taking a long time? How can this initialization time be reduced?
OS: Ubuntu 16.04
CUDA: 10.0
CUDNN: 7.0
GPU: NVIDIA V100
libtorch build version: 1.0.1
Thank you!