Dear all,
Recently, I work on this loss function which has a special L2 norm constraint.
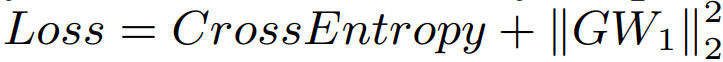
The G denotes the first derivative matrix for the first layer in the neural network. I try to search for a lot of methods. However, it can not work for this constraint. How can I implement this constraint? To write a new autograd function for the first layer in the neural network? or implement a new optimizer?
Thank you for your kindest help!