I want to use PyTorch to fit the sine curve.
I have the points of the sine curve with given frequency f_trurh and a sine function with an input parameter f.
However, I am facing an issue where the fit process does not seem to work properly. The Adam optimizer gets stuck in a local minima closest to the initial frequency value f_0.
Could you please help me understand what might be causing this problem?
Below is the code and some figures, might be helpful to understand the problem.
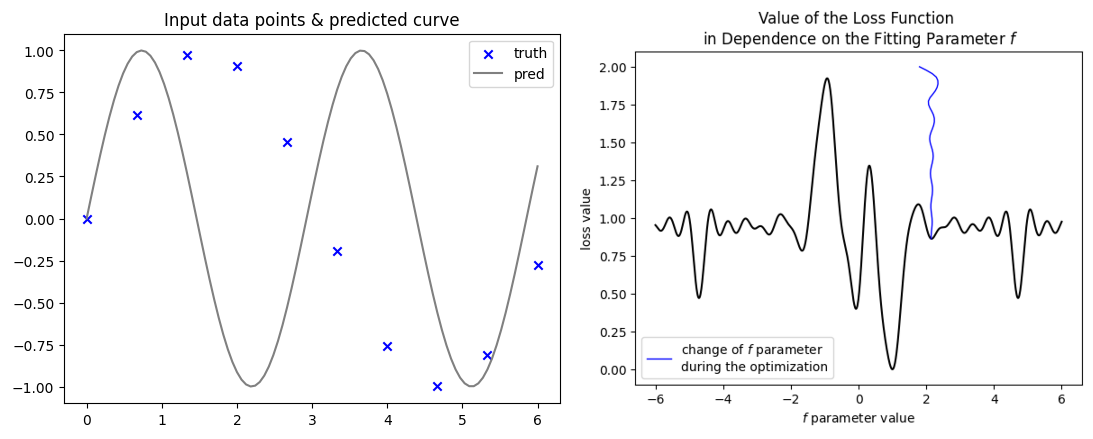
You can plot the loss function and see that from f_0 = 1.8 you’ll go in the wrong direction.
E.g.
losses = [(x/50, loss_fn(torch.sin( torch.linspace(0, 6, 20) ), torch.sin( (x/50) * torch.linspace(0, 6, 20) ) )) for x in range(0, 100) ]
plt.plot( [x[0] for x in losses], [x[1] for x in losses] )
shows that f_0 > ~ 1.75 or < about 0.3 is going to learn to move in the wrong direction away from the global optimum.
Looking at your own graph of the input data and predicted curve, think about how close the high and low of the predicted sin curve are from (points on) the actual sin curve, and how much farther they’d (temporarily) need to move away from optimal values before finally arriving at the optimal solution.
I indeed understand that standard gradient descent would work in this case only if the initial parameter value is close enough to the global minimum. However, I believe that more complicated optimizers should handle the local minima problem.
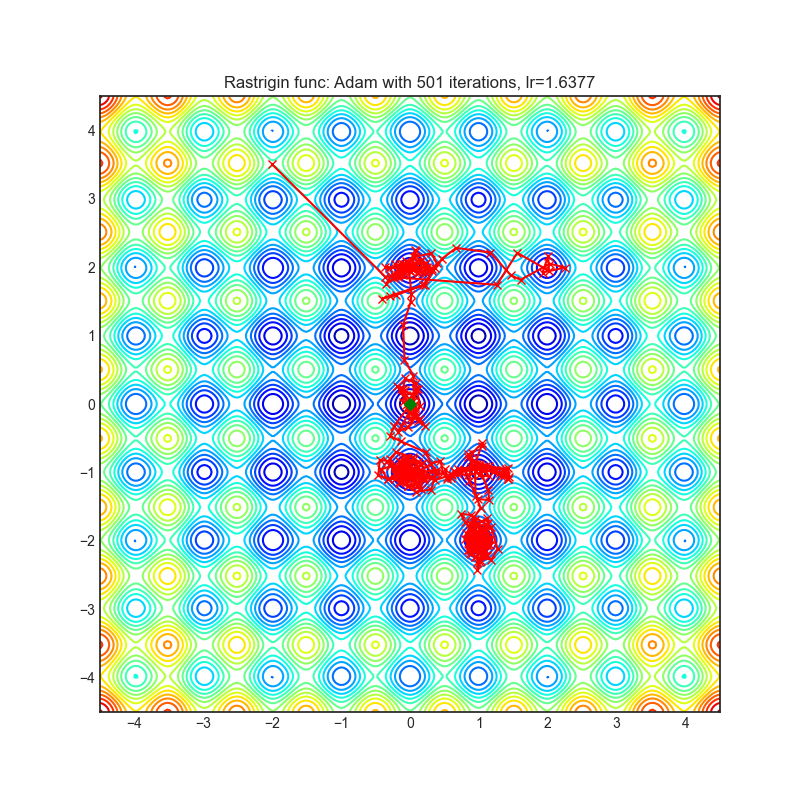
For instance, there is an example of PyTorch’s built-in Adam optimizer dealing with the local minima problem: (image).
So, I guess, in my particular case, there should also be a way to solve the problem for less strict initial conditions. And the question is how to do it.
That’s right, there are cases where an optimizer step can step right past a local minimum. A high learning rate can cause that, and so can a momentum factor. A high lr or momentum can also cause problems – you want to avoid local minima but not the global one. In most situations, you wouldn’t want to choose a learning rate greater than one.
{kind=link}