So, I’m currently trying to build a custom-built LSTM model. To do so, I’m trying to build the custom LSTM from scratch first and slowly modify it. However, right now I’m having difficultly making the model learn at all.
Here is my code for the my LSTM function.
class LSTM_Model(nn.Module):
def __init__(self, input_sz, hidden_sz, out_sz, bs):
super().__init__()
self.input_sz = input_sz
self.hidden_size = hidden_sz
self.W = nn.Parameter(torch.Tensor(input_sz, hidden_sz * 4))
self.U = nn.Parameter(torch.Tensor(hidden_sz, hidden_sz * 4))
self.bias = nn.Parameter(torch.Tensor(hidden_sz * 4))
self.fc1 = nn.Linear(hidden_sz, out_sz)
self.init_weights()
def init_weights(self):
stdv = 1.0 / math.sqrt(self.hidden_size)
for weight in self.parameters():
weight.data.uniform_(-stdv, stdv)
def forward(self, x, init_states=None):
bs, seq_sz, _ = x.size()
hidden_seq = []
if init_states is None:
h_t, c_t = (torch.zeros(bs, self.hidden_size).to(x.device),
torch.zeros(bs, self.hidden_size).to(x.device))
else:
h_t, c_t = init_states
for t in range(seq_sz):
x_t = x[:, t, :]
if x_t.size()[0] != bs:
fill_in = torch.zeros(bs-x_t[0], seq_sz)
x_t - torch.cat((x_t, fill_in), 0)
gates = torch.matmul(x_t, self.W) + torch.matmul(h_t, self.U) + self.bias
i_t, f_t, g_t, o_t = gates.chunk(4, 1)
i_t, f_t, g_t, o_t = torch.sigmoid(i_t), torch.sigmoid(f_t), torch.tanh(g_t), torch.sigmoid(i_t)
c_t = f_t * c_t + i_t * g_t
h_t = o_t * torch.tanh(c_t)
hidden_seq.append(h_t)
out = self.fc1(h_t)
return out, (h_t, c_t)
Here is my training function.
def train_model(data_loader, model, loss_function, optimizer):
num_batches = len(data_loader)
total_loss = 0
model.train()
hidden = None
#torch.autograd.set_detect_anomaly(True)
for X, y in data_loader:
output, hidden = model(X, hidden)
loss = loss_function(output, y)
optimizer.zero_grad()
loss.backward()
#loss.backward(retain_graph=True)
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / num_batches
print(f"Train loss: {avg_loss}")
return avg_loss
Running it gets an initial error message, which requires me to put the retain_graph(True), but after that I get more errors.
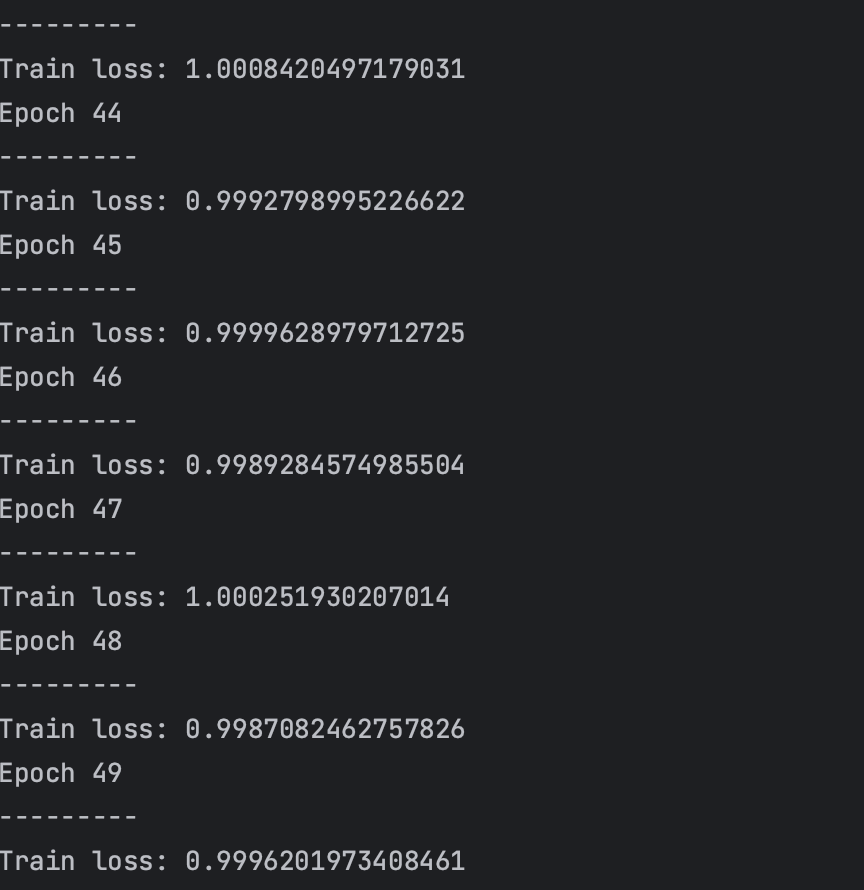
I also notice that removing the hidden variable for the training function, the program gives an output, but the model does not learn at all, probably because it’s throwing away the hidden state I think.
Yea, but I have no idea what’s going wrong. Please help.