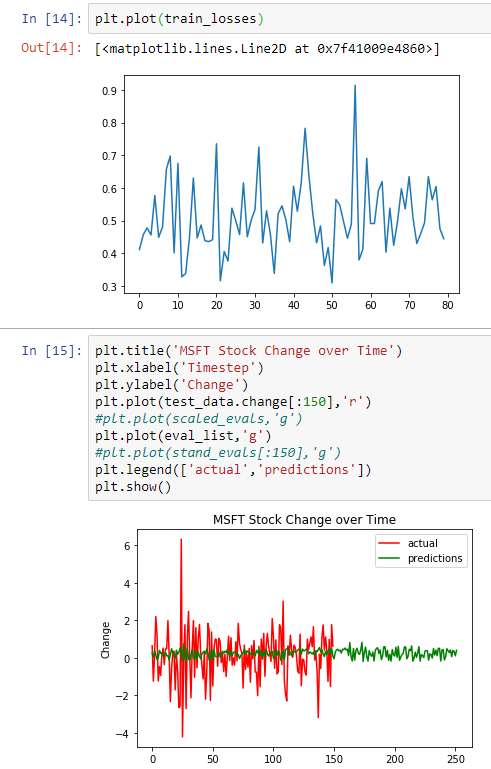
Hi, I’m a noob at pytorch and just started using it 1 week ago. I am trying to train an RNN on some scaled, modified stock data, using inputs with multiple features to try and predict a single output(I’m interested in only 1 feature of the data). I do this by repeatedly, randomly sampling 3 timesteps to predict the next timestep, and compare it to the labels for the training data, to ultimately train the model, get the loss, and update the weights. The model predicts an output which has the same dimensions as the input, but I coded it to only get the single value at the index of the feature I’m interested in, hence outputting a a value of a single dimension.
However, as I try to train the model, the loss fluctuates greatly(indicated by the graph), and for some reason my predictions, when graphed against the actual targets, are very small. What could be accounting for this? Also, I don’t formally know comp sci, so my code might not be the best(I’m a self-learner).
##load data and modify data
pre_data=pd.read_csv('MSFTmod.csv')
pre_data=pre_data.drop(['date','Unnamed: 0','changeOverTime'],axis=1)
labels=pre_data.columns
scaler = MinMaxScaler(feature_range=(-1, 1))
standardizer=StandardScaler()
data=standardizer.fit_transform(pre_data)
#data=scaler.fit_transform(pre_data)
data=pd.DataFrame(data,columns=labels)
train_data= data[0:round(0.8*data.shape[0])] #80% of first data will be for training
test_data= data[round(0.8*data.shape[0]):]
test_data=test_data.reset_index().drop('index',axis=1)
change_ind=test_data.columns.get_loc('change')
test_data.head()
#Get random sequence from the train_data
def rand_seq(seq_len=seq_len):
#seq_len = 3 # length of an input sequence
start_index = random.randint(0, len(train_data) - seq_len)
end_index = start_index+seq_len+1 #input takes first 3, target takes last 3
rand_seq=train_data[start_index:end_index]
return rand_seq
#Split into input and target
def Extract_Train(batch_size=batch_size):
seq = rand_seq()
train_inputs = torch.from_numpy(seq.iloc[:-1,:].values.astype(np.float32)) #input of shape (seq_len, batch, input_size)
#train_targets = torch.from_numpy(seq.iloc[1:,:].values.astype(np.float32))
train_targets= torch.from_numpy(seq.iloc[1:,change_ind].values.astype(np.float32))
train_inputs=torch.reshape(train_inputs,(len(train_inputs), batch_size, input_size))
train_targets=torch.reshape(train_targets,(-1, batch_size,change_size))
return train_inputs.to(device), train_targets.to(device)
#get retraining data to retrain initialized hidden-state for predicting
retrain_inputs=torch.from_numpy(train_data.iloc[-5:,:].values.astype(np.float32)) #5 timesteps to iterate over, iterating over 3 times
retrain_inputs=torch.reshape(retrain_inputs,(retrain_inputs.shape[0], batch_size, input_size)) #get testing data from remainder of samples
test_inputs = torch.from_numpy(test_data.iloc[:-1,:].values.astype(np.float32))
#test_targets = torch.from_numpy(test_data.iloc[1:,:].values.astype(np.float32))
test_targets= torch.from_numpy(test_data.iloc[1:,change_ind].values.astype(np.float32))
test_inputs=torch.reshape(test_inputs,(test_inputs.shape[0], batch_size, input_size))
test_targets=torch.reshape(test_targets,(test_targets.shape[0], batch_size, change_size))
#test_targets=torch.reshape(test_targets,(test_targets.shape[0], batch_size, output_size))
test_inputs, test_targets, retrain_inputs= test_inputs.to(device), test_targets.to(device), retrain_inputs.to(device)type or paste code here
class Net(nn.Module):
def __init__(self,input_size,hidden_size,output_size,batch_size):
super(Net, self).__init__()
self.hidden_size=hidden_size
self.batch_size= batch_size
self.output_size=output_size
#self.input_size=input_size
self.rnn= nn.RNNCell(input_size,hidden_size)#,nonlinearity= 'relu')
self.linear=nn.Linear(self.hidden_size,self.output_size)
def forward(self, inputs, hidden):
#hidden=self.rnn(inputs,hidden)
hidden= self.rnn(inputs.detach(),hidden.detach())
output= self.linear(hidden)
change=output[0][change_ind]
return output, hidden, change
def init_hidden(self):
return torch.zeros(self.batch_size, self.hidden_size).to(device)
net=Net(input_size,hidden_size,output_size,batch_size)
net.to(device)
## train step that is to be iterated by number of epochs
def train_step(net,opt,loss_func):
train_inputs, train_targets= Extract_Train()
seq_len = train_inputs.shape[0] # Get the sequence length of current input.
hidden = net.init_hidden() # Initial hidden state.
net.zero_grad() # Clear the gradient.
loss = 0 # Initial loss.
for t in range(seq_len): # For each one in the input sequence.
output, hidden, change = net(train_inputs[t], hidden)
#loss = loss + loss_func(output, train_targets[t])
loss= loss+ loss_func(change,train_targets[t])
loss.backward() # Backward.
opt.step() # Update the weights.
avg_loss= loss / seq_len
return avg_loss # Return the average loss w.r.t sequence length.
#Actual test inputs as inputs:
def eval_step(net, loss_func, retrain_inputs,seq_len):
#seq_len= 3
eval_iter=len(test_targets)
retrain_iter=len(retrain_inputs)
eval_list=[]
loss=0
eval_loss=[]
retrain_inputs=torch.cat((retrain_inputs,test_inputs[0:seq_len-1]),dim=0)
net.eval()
with torch.no_grad():
hidden=net.init_hidden()
for i in range(retrain_iter):
retrain=retrain_inputs[i:i+seq_len,:]
if retrain.shape[0]==seq_len:
for t in range(seq_len):
output, _, change=net(retrain[t],hidden)
if i>=2:
loss=loss+loss_func(change,test_targets[t])
else:
continue
if i>=2:
avg_loss=loss/seq_len
eval_list.append(change)
eval_loss.append(avg_loss)
loss=0
else:
continue
else:
break
for i in range(eval_iter):
retest=test_inputs[i:i+seq_len,:]
if retest.shape[0]==seq_len:
for t in range(seq_len):
output,_, change= net(retest[t], hidden)
loss= loss_func(change, test_targets[t])
eval_list.append(change)
avg_loss= loss/seq_len
eval_loss.append(avg_loss)
loss=0
else:
break
return eval_list, eval_loss
train_losses=[]
training_iterations= 8000 #8000
loss_sum=0
for iteration in range(training_iterations):
avg_loss=train_step(net, opt, loss_func)
loss_sum= loss_sum + avg_loss
if (iteration % 100) == 99:
train_losses.append(loss_sum/100)
loss_sum=0
eval_list, eval_loss=eval_step(net, loss_func, retrain_inputs,seq_len)