Hi, I am trying to use slicing to reduce the peak memory in my model, a simple example of what I am doing is the following:
# x: Input, [10000, 256]
# w1: Weight, [256, 1024]
# w2: Weight, [1024, 256]
y = torch.matmul(torch.matmul(x, w1), w2)
Since directly calculating y will create an intermediate activation of [10000, 1024], I want to use a for loop and hope it can reduce the peak memory:
chunk_size = 2500
num_chunks = int(x.shape[0] / chunk_size)
y = torch.empty_like(x)
for i in range(num_chunks):
st = i * chunk_size
ed = st + chunk_size
y[st:ed] = torch.matmul(torch.matmul(x[st:ed], w1), w2)
By doing so, ideally, each for loop only creates an intermediate activation of [2500, 1024], therefore the peak memory can be reduced.
However, I use pytorch profiler to profile the memory, I found that despite the forward process seeing a decrease in memory, the backward process somehow gets a new memory spike as shown below:
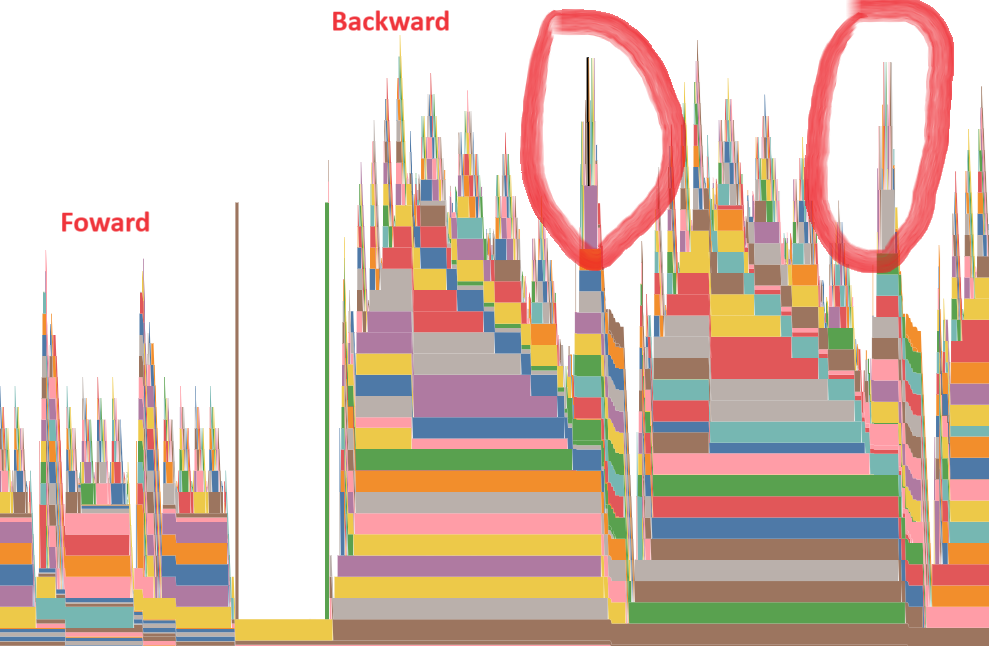
The marked circles are named like wrapper_CompositeExplicitAutograd__slice_backward, the full description is:
CUDACachingAllocator.cpp:0:c10::cuda::CUDACachingAllocator::Native::DeviceCachingAllocator::malloc(int, unsigned long, CUstream_st*)
:0:c10::cuda::CUDACachingAllocator::Native::NativeCachingAllocator::malloc(void**, int, unsigned long, CUstream_st*)
:0:c10::cuda::CUDACachingAllocator::Native::NativeCachingAllocator::allocate(unsigned long) const
:0:at::TensorBase at::detail::_empty_generic<long>(c10::ArrayRef<long>, c10::Allocator*, c10::DispatchKeySet, c10::ScalarType, std::optional<c10::MemoryFormat>)
??:0:at::detail::empty_generic(c10::ArrayRef<long>, c10::Allocator*, c10::DispatchKeySet, c10::ScalarType, std::optional<c10::MemoryFormat>)
??:0:at::detail::empty_cuda(c10::ArrayRef<long>, c10::ScalarType, std::optional<c10::Device>, std::optional<c10::MemoryFormat>)
??:0:at::detail::empty_cuda(c10::ArrayRef<long>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>, std::optional<c10::MemoryFormat>)
??:0:at::native::empty_cuda(c10::ArrayRef<long>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>, std::optional<c10::MemoryFormat>)
RegisterCUDA.cpp:0:at::(anonymous namespace)::(anonymous namespace)::wrapper_CUDA_memory_format_empty(c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>, std::optional<c10::MemoryFormat>)
RegisterCUDA.cpp:0:c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoFunctor_<c10::CompileTimeFunctionPointer<at::Tensor (c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>, std::optional<c10::MemoryFormat>), &at::(anonymous namespace)::(anonymous namespace)::wrapper_CUDA_memory_format_empty>, at::Tensor, c10::guts::typelist::typelist<c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>, std::optional<c10::MemoryFormat> > >, at::Tensor (c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>, std::optional<c10::MemoryFormat>)>::call(c10::OperatorKernel*, c10::DispatchKeySet, c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>, std::optional<c10::MemoryFormat>)
??:0:at::_ops::empty_memory_format::redispatch(c10::DispatchKeySet, c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>, std::optional<c10::MemoryFormat>)
RegisterBackendSelect.cpp:0:c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoFunctor_<c10::CompileTimeFunctionPointer<at::Tensor (c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>, std::optional<c10::MemoryFormat>), &at::(anonymous namespace)::empty_memory_format>, at::Tensor, c10::guts::typelist::typelist<c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>, std::optional<c10::MemoryFormat> > >, at::Tensor (c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>, std::optional<c10::MemoryFormat>)>::call(c10::OperatorKernel*, c10::DispatchKeySet, c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>, std::optional<c10::MemoryFormat>)
??:0:at::_ops::empty_memory_format::call(c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>, std::optional<c10::MemoryFormat>)
??:0:at::native::zeros_symint(c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>)
RegisterCompositeExplicitAutograd.cpp:0:c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoFunctor_<c10::CompileTimeFunctionPointer<at::Tensor (c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>), &at::(anonymous namespace)::(anonymous namespace)::wrapper_CompositeExplicitAutograd__zeros>, at::Tensor, c10::guts::typelist::typelist<c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool> > >, at::Tensor (c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>)>::call(c10::OperatorKernel*, c10::DispatchKeySet, c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>)
??:0:at::_ops::zeros::redispatch(c10::DispatchKeySet, c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>)
RegisterBackendSelect.cpp:0:c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoFunctor_<c10::CompileTimeFunctionPointer<at::Tensor (c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>), &at::(anonymous namespace)::zeros>, at::Tensor, c10::guts::typelist::typelist<c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool> > >, at::Tensor (c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>)>::call(c10::OperatorKernel*, c10::DispatchKeySet, c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>)
??:0:at::_ops::zeros::call(c10::ArrayRef<c10::SymInt>, std::optional<c10::ScalarType>, std::optional<c10::Layout>, std::optional<c10::Device>, std::optional<bool>)
??:0:at::native::slice_backward(at::Tensor const&, c10::ArrayRef<long>, long, long, long, long)
RegisterCompositeExplicitAutograd.cpp:0:at::(anonymous namespace)::(anonymous namespace)::wrapper_CompositeExplicitAutograd__slice_backward(at::Tensor const&, c10::ArrayRef<c10::SymInt>, long, c10::SymInt, c10::SymInt, c10::SymInt)
RegisterCompositeExplicitAutograd.cpp:0:c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoFunctor_<c10::CompileTimeFunctionPointer<at::Tensor (at::Tensor const&, c10::ArrayRef<c10::SymInt>, long, c10::SymInt, c10::SymInt, c10::SymInt), &at::(anonymous namespace)::(anonymous namespace)::wrapper_CompositeExplicitAutograd__slice_backward>, at::Tensor, c10::guts::typelist::typelist<at::Tensor const&, c10::ArrayRef<c10::SymInt>, long, c10::SymInt, c10::SymInt, c10::SymInt> >, at::Tensor (at::Tensor const&, c10::ArrayRef<c10::SymInt>, long, c10::SymInt, c10::SymInt, c10::SymInt)>::call(c10::OperatorKernel*, c10::DispatchKeySet, at::Tensor const&, c10::ArrayRef<c10::SymInt>, long, c10::SymInt, c10::SymInt, c10::SymInt)
:0:at::Tensor c10::callUnboxedKernelFunction<at::Tensor, at::Tensor const&, c10::ArrayRef<c10::SymInt>, long, c10::SymInt, c10::SymInt, c10::SymInt>(void*, c10::OperatorKernel*, c10::DispatchKeySet, at::Tensor const&, c10::ArrayRef<c10::SymInt>&&, long&&, c10::SymInt&&, c10::SymInt&&, c10::SymInt&&)
:0:at::Tensor c10::Dispatcher::redispatch<at::Tensor, at::Tensor const&, c10::ArrayRef<c10::SymInt>, long, c10::SymInt, c10::SymInt, c10::SymInt>(c10::TypedOperatorHandle<at::Tensor (at::Tensor const&, c10::ArrayRef<c10::SymInt>, long, c10::SymInt, c10::SymInt, c10::SymInt)> const&, c10::DispatchKeySet, at::Tensor const&, c10::ArrayRef<c10::SymInt>, long, c10::SymInt, c10::SymInt, c10::SymInt) const
??:0:at::_ops::slice_backward::redispatch(c10::DispatchKeySet, at::Tensor const&, c10::ArrayRef<c10::SymInt>, long, c10::SymInt, c10::SymInt, c10::SymInt)
VariableType_3.cpp:0:torch::autograd::VariableType::(anonymous namespace)::slice_backward(c10::DispatchKeySet, at::Tensor const&, c10::ArrayRef<c10::SymInt>, long, c10::SymInt, c10::SymInt, c10::SymInt)
VariableType_3.cpp:0:c10::impl::wrap_kernel_functor_unboxed_<c10::impl::detail::WrapFunctionIntoFunctor_<c10::CompileTimeFunctionPointer<at::Tensor (c10::DispatchKeySet, at::Tensor const&, c10::ArrayRef<c10::SymInt>, long, c10::SymInt, c10::SymInt, c10::SymInt), &torch::autograd::VariableType::(anonymous namespace)::slice_backward>, at::Tensor, c10::guts::typelist::typelist<c10::DispatchKeySet, at::Tensor const&, c10::ArrayRef<c10::SymInt>, long, c10::SymInt, c10::SymInt, c10::SymInt> >, at::Tensor (c10::DispatchKeySet, at::Tensor const&, c10::ArrayRef<c10::SymInt>, long, c10::SymInt, c10::SymInt, c10::SymInt)>::call(c10::OperatorKernel*, c10::DispatchKeySet, at::Tensor const&, c10::ArrayRef<c10::SymInt>, long, c10::SymInt, c10::SymInt, c10::SymInt)
:0:at::Tensor c10::callUnboxedKernelFunction<at::Tensor, at::Tensor const&, c10::ArrayRef<c10::SymInt>, long, c10::SymInt, c10::SymInt, c10::SymInt>(void*, c10::OperatorKernel*, c10::DispatchKeySet, at::Tensor const&, c10::ArrayRef<c10::SymInt>&&, long&&, c10::SymInt&&, c10::SymInt&&, c10::SymInt&&)
??:0:at::_ops::slice_backward::call(at::Tensor const&, c10::ArrayRef<c10::SymInt>, long, c10::SymInt, c10::SymInt, c10::SymInt)
:0:torch::autograd::generated::details::slice_backward_wrapper(at::Tensor const&, c10::ArrayRef<c10::SymInt> const&, long, std::optional<c10::SymInt>, std::optional<c10::SymInt>, c10::SymInt)
??:0:torch::autograd::generated::SliceBackward0::apply(std::vector<at::Tensor, std::allocator<at::Tensor> >&&)
:0:torch::autograd::Node::operator()(std::vector<at::Tensor, std::allocator<at::Tensor> >&&)
??:0:torch::autograd::Engine::evaluate_function(std::shared_ptr<torch::autograd::GraphTask>&, torch::autograd::Node*, torch::autograd::InputBuffer&, std::shared_ptr<torch::autograd::ReadyQueue> const&)
??:0:torch::autograd::Engine::thread_main(std::shared_ptr<torch::autograd::GraphTask> const&)
??:0:torch::autograd::Engine::execute_with_graph_task(std::shared_ptr<torch::autograd::GraphTask> const&, std::shared_ptr<torch::autograd::Node>, torch::autograd::InputBuffer&&)
??:0:torch::autograd::python::PythonEngine::execute_with_graph_task(std::shared_ptr<torch::autograd::GraphTask> const&, std::shared_ptr<torch::autograd::Node>, torch::autograd::InputBuffer&&)
??:0:torch::autograd::Engine::execute(std::vector<torch::autograd::Edge, std::allocator<torch::autograd::Edge> > const&, std::vector<at::Tensor, std::allocator<at::Tensor> > const&, bool, bool, bool, std::vector<torch::autograd::Edge, std::allocator<torch::autograd::Edge> > const&)
??:0:torch::autograd::python::PythonEngine::execute(std::vector<torch::autograd::Edge, std::allocator<torch::autograd::Edge> > const&, std::vector<at::Tensor, std::allocator<at::Tensor> > const&, bool, bool, bool, std::vector<torch::autograd::Edge, std::allocator<torch::autograd::Edge> > const&)
??:0:THPEngine_run_backward(_object*, _object*, _object*)
And as I use smaller chunk_size (i.e. more slices), this part of memory keeps increasing.
From what I understand, during backpropagation, pytorch is trying to create a gradient for each slice, and store them all in memory before accumulating them. I am wondering why it cannot just perform the exact for loop during backward, and accumulating gradients after each loop, since in this case, the peak memory can be kept low.