Here is the model :
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import math
import torch
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
BN_MOMENTUM = 0.01
model_urls = {
'mobilenet_v2': 'https://download.pytorch.org/models/mobilenet_v2-b0353104.pth',
}
def conv_bn(inp, oup, stride):
conv_3x3 = nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True)
)
for m in conv_3x3.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
return conv_3x3
def conv_1x1_bn(inp, oup):
conv1x1 = nn.Sequential(
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True))
for m in conv1x1.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
return conv1x1
def deconv_bn_relu(in_channels, out_channels, kernel_size, padding, output_padding, bias):
deconv = nn.Sequential(
nn.ConvTranspose2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=2,
padding=padding,
output_padding=output_padding,
bias=bias),
nn.BatchNorm2d(out_channels, momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)
)
for m in deconv.modules():
if isinstance(m, nn.ConvTranspose2d):
fill_up_weights(m)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
return deconv
def fill_fc_weights(layers):
for m in layers.modules():
if isinstance(m, nn.Conv2d):
if m.bias is not None:
nn.init.constant_(m.bias, 0)
def fill_up_weights(up):
w = up.weight.data
f = math.ceil(w.size(2) / 2)
c = (2 * f - 1 - f % 2) / (2. * f)
for i in range(w.size(2)):
for j in range(w.size(3)):
w[0, 0, i, j] = \
(1 - math.fabs(i / f - c)) * (1 - math.fabs(j / f - c))
for c in range(1, w.size(0)):
w[c, 0, :, :] = w[0, 0, :, :]
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_dim = round(inp * expand_ratio)
self.use_res_connect = self.stride == 1 and inp == oup
if expand_ratio == 1:
self.conv = nn.Sequential(
# dw
nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.ReLU(inplace=True),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
# pw
nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.ReLU(inplace=True),
# dw
nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.ReLU(inplace=True),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
class MobileNetv2Det(nn.Module):
def __init__(self, heads, head_conv, width_mult=1., is_train=True):
super(MobileNetv2Det, self).__init__()
self.inplanes = 32
self.last_channel = 64 # backbone
self.deconv_with_bias = False
self.is_train = is_train
self.heads = heads
block = InvertedResidual
interverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
# build backbone
# building first layer
# assert input_size % 32 == 0
input_channel = int(self.inplanes * width_mult)
self.last_channel = int(self.last_channel * width_mult) if width_mult > 1.0 else self.last_channel
self.features = [conv_bn(3, input_channel, 2)]
# building inverted residual blocks
for t, c, n, s in interverted_residual_setting:
output_channel = int(c * width_mult)
for i in range(n):
if i == 0:
self.features.append(block(input_channel, output_channel, s, expand_ratio=t))
else:
self.features.append(block(input_channel, output_channel, 1, expand_ratio=t))
input_channel = output_channel
# make it nn.Sequential
self.features = nn.Sequential(*self.features)
# building last several layers
self.backbone_lastlayer = conv_1x1_bn(input_channel, self.last_channel)
self.ups = []
for i in range(3):
up = deconv_bn_relu(self.last_channel, self.last_channel, 2, 0, 0, self.deconv_with_bias)
self.ups.append(up)
self.ups = nn.Sequential(*self.ups)
self.conv_dim_matchs = []
self.conv_dim_matchs.append(conv_1x1_bn(96, self.last_channel))
self.conv_dim_matchs.append(conv_1x1_bn(32, self.last_channel))
self.conv_dim_matchs.append(conv_1x1_bn(24, self.last_channel))
self.conv_dim_matchs = nn.Sequential(*self.conv_dim_matchs)
self.last_context_conv = conv_bn(self.last_channel, self.last_channel, 1)
for head in sorted(self.heads):
num_output = self.heads[head]
if head_conv > 0:
fc = nn.Sequential(
nn.Conv2d(self.last_channel, head_conv,
kernel_size=3, padding=1, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(head_conv, num_output,
kernel_size=1, stride=1, padding=0))
if 'hm' in head:
fc[-1].bias.data.fill_(-2.19)
else:
fill_fc_weights(fc)
else:
fc = nn.Conv2d(
in_channels=self.last_channel,
out_channels=num_output,
kernel_size=1,
stride=1,
padding=0
)
if 'hm' in head:
fc.bias.data.fill_(-2.19)
else:
fill_fc_weights(fc)
self.__setattr__(head, fc)
def init_weights(self, pretrained=True):
if pretrained:
for head in self.heads:
final_layer = self.__getattr__(head)
for i, m in enumerate(final_layer.modules()):
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.weight.shape[0] == self.heads[head]:
if 'hm' in head:
nn.init.constant_(m.bias, -2.19)
else:
nn.init.normal_(m.weight, std=0.001)
nn.init.constant_(m.bias, 0)
url = model_urls['mobilenet_v2']
pretrained_state_dict = model_zoo.load_url(url)
print('=> loading pretrained model {}'.format(url))
self.features.load_state_dict(pretrained_state_dict, strict=False)
else:
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.ConvTranspose2d):
fill_up_weights(m)
if m.bias is not None:
nn.init.zeros_(m.bias)
def forward(self, x):
xs = []
for n in range(0, 4):
x = self.features[n](x)
xs.append(x)
for n in range(4, 7):
x = self.features[n](x)
xs.append(x)
for n in range(7, 14):
x = self.features[n](x)
xs.append(x)
for n in range(14, 18):
x = self.features[n](x)
x = self.backbone_lastlayer(x)
for i in range(3):
x = self.ups[i](x)
x = x + self.conv_dim_matchs[i](xs[3 - i - 1])
x = self.last_context_conv(x)
if self.is_train == True:
ret = {}
for head in self.heads:
ret[head] = self.__getattr__(head)(x)
return [ret]
else:
ret = []
for head in self.heads:
ret.append(self.__getattr__(head)(x))
return torch.cat(ret, 1)
def get_mv2relu_net(num_layers, heads, head_conv, is_train):
model = MobileNetv2Det(heads, head_conv=head_conv, width_mult=1.0, is_train=is_train)
model.init_weights()
return model
def create_model(heads={'hm': 1, 'wh': 2, 'reg': 2}, head_conv=64, is_train=True):
model = get_mv2relu_net(num_layers=0, heads=heads, head_conv=head_conv, is_train=is_train)
return model
def demo():
model = create_model(is_train=False).cuda()
model.init_weights()
model = model.eval()
model.is_train = False
model.eval()
random_sample = torch.rand(2, 3, 640, 640).cuda()
out = model(random_sample)
traced_module = torch.jit.trace(model, random_sample)
traced_module.save("traced_model.pt")
if __name__ == '__main__':
demo()
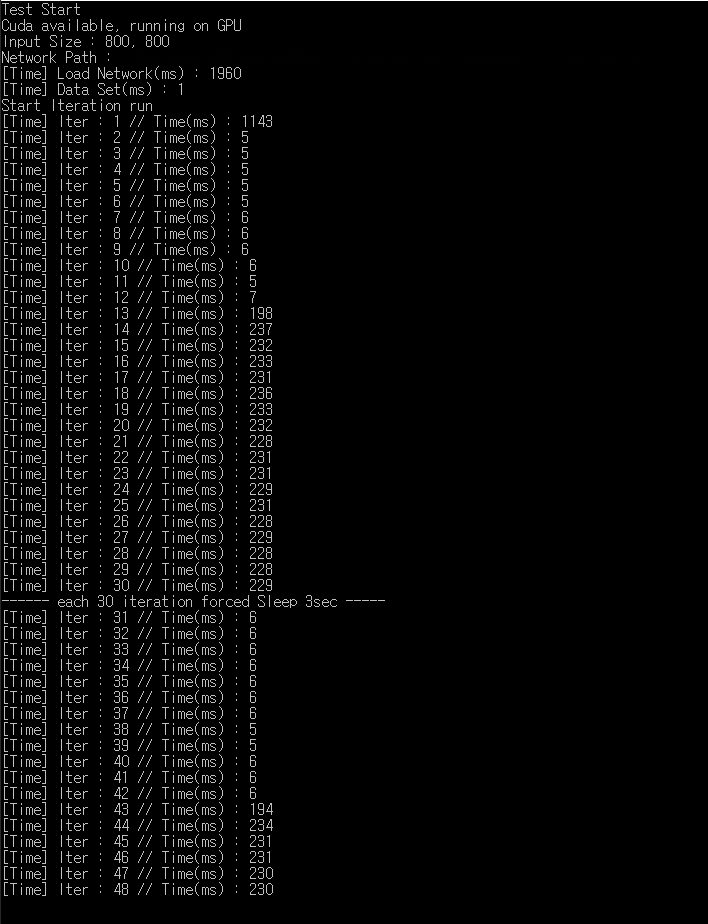
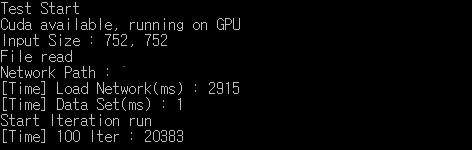
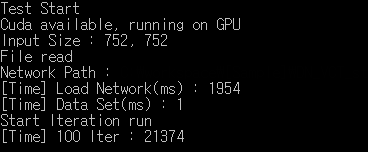

 it happen to me as well. I Syncronized the gpu and the problem still persist.
it happen to me as well. I Syncronized the gpu and the problem still persist.