I am training the following network:
[https://user-images.githubusercontent.com/544269/43301916-d633fcc6-91a2-11e8-8e21-86c9544f71d0.png]
My dataset is 512x512x500 CT data.
My training was very slow and profiling gave the following output:
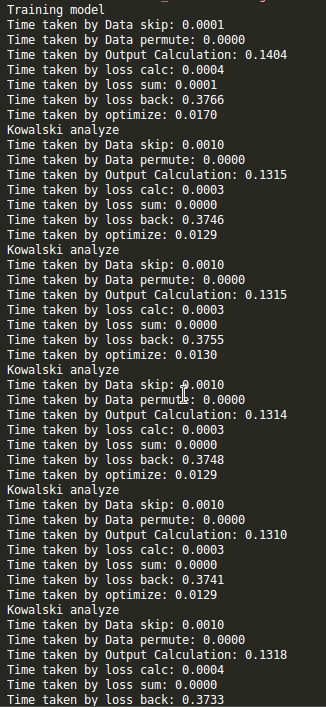
{kind=link}
Are these time complexities expected for the forward, loss.backward and optimize steps?
Loss.backward() is the slowest step. I can understand forward calculation and loss.backward having similar time complexity, but what’s the reason for optimize step being ~30x faster? Are all the weight updates happening simultaneously, while loss.backward is sequential?
Thanks!