I’ve tried to run WGAN model and meet some strange behavior. I’m not sure is it my bug, or pytorch bug. I made a minimal example to discuss it here.
So, we have an error
RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time.
But if you look into the gist you can find my comments on how to change it to run successfully. For example, I don’t understand how inplace ReLu operations infuence on this error (note http://i.imgur.com/6H26H6o.png).
Main questions: can you explain why it works this way? Why those errors occur?
Details: pytorch 0.4.1, ubuntu 16.04, GeForce 1080TI
Note 1. Module BrokenBlock has no parameters. You can check it using the folowing code:
b = BrokenBlock(3)
for p in b.parameters():
print(p.data.size())
And if it has no parameters then backward should not walk through it. But changing ReLu(inplace=False) in BrokenBlock somehow influences the backward to walk successfully.


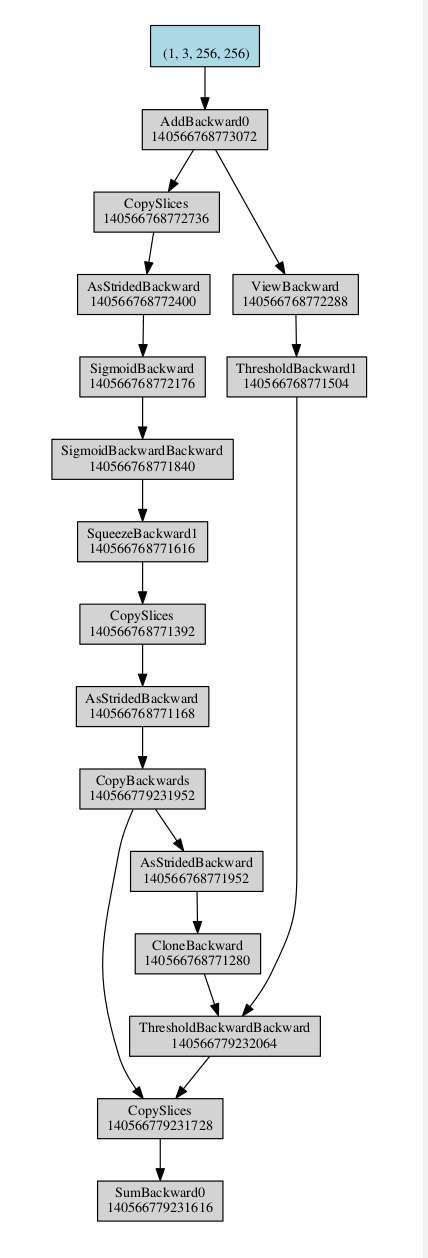
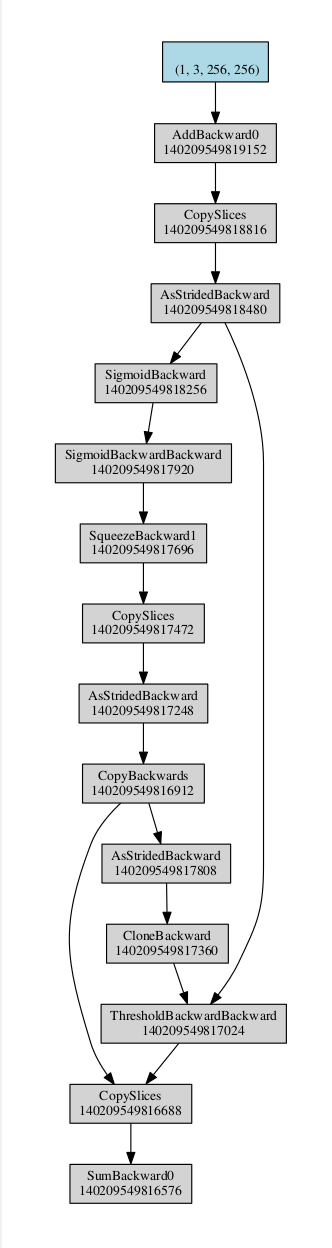
 . And also I understand that I can use
. And also I understand that I can use {kind=link}