I’ll add more informations here for future reference.
The corresponding PR to fix it is here.
Smallest repro code:
import torch
from torch import nn, cuda
from torch.autograd import Variable, grad
from torch.nn import functional as F
# Debug stuff
import torchviz
torch.autograd.set_detect_anomaly(True)
inputs = torch.ones((1, 3, 256, 256), requires_grad=True)
tmp1 = (inputs+1).view_as(inputs)
tmp2 = F.threshold(tmp1, 0., 0., True)
prob_interpolated = torch.sigmoid(tmp2)
gradients = grad(outputs=prob_interpolated, inputs=inputs,
grad_outputs=torch.ones(prob_interpolated.size()),
create_graph=True, retain_graph=True)[0]
gradient_penalty = gradients.sum()
# Debug graph
torchviz.make_dot(gradient_penalty).view()
gradient_penalty.backward()
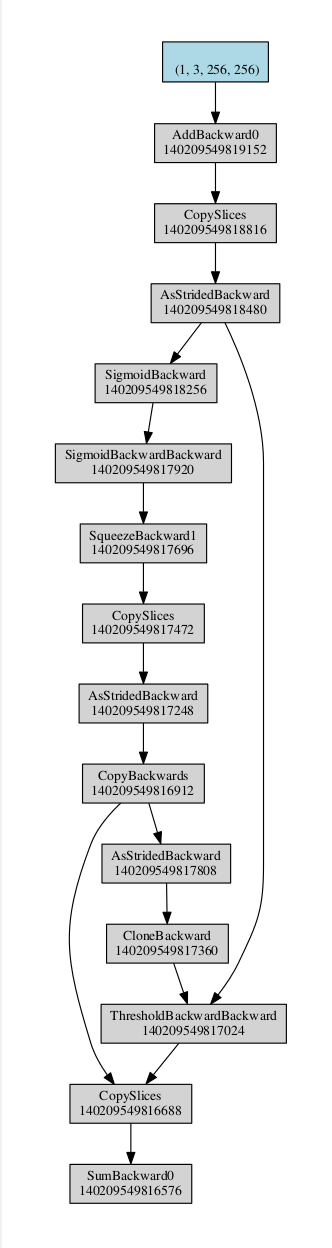
The computational graph generated is:
The interesting part is the branch on the right that links ThresholdBackwardBackward directly to ThresholdBackward while ThresholdBackward is already wrapped inside the first CopySlices.
The thing is that part of the threshold_ function code is:
baseType->threshold_(self_, threshold, value);
increment_version(self);
rebase_history(flatten_tensor_args( self ), grad_fn);
if (tracer_state) {
jit::tracer::setTracingState(std::move(tracer_state));
jit::tracer::addOutput(node, self);
}
if (grad_fn) {
grad_fn->result_ = SavedVariable(self, true);
}
As you can see, self is considered as an output of grad_fn when saved. And so when ThresholdBackward is called to generate ThresholdBackwardBackward, self is associated to ThresholdBackward and thus the graph above.
The thing is that after the rebase_history, self is not an output of grad_fn anymore, it’s an output of the rewritten graph.
Changing the save to
grad_fn->result_ = SavedVariable(self, !as_variable_ref(self).is_view());
Make sure that in the case where self’s history is rewritten, we don’t consider it as an output of grad_fn anymore.
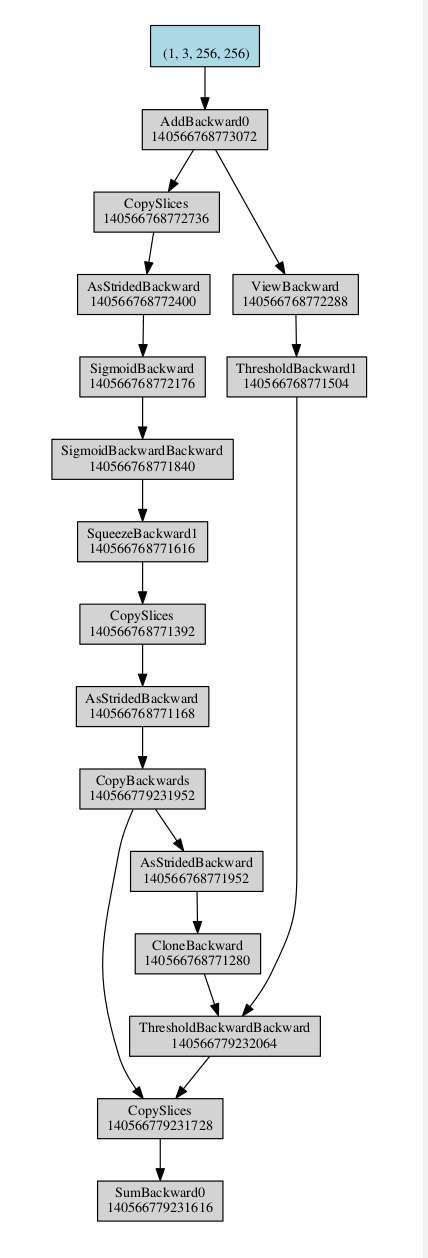
After the fix in the PR, the new graph is as expected: