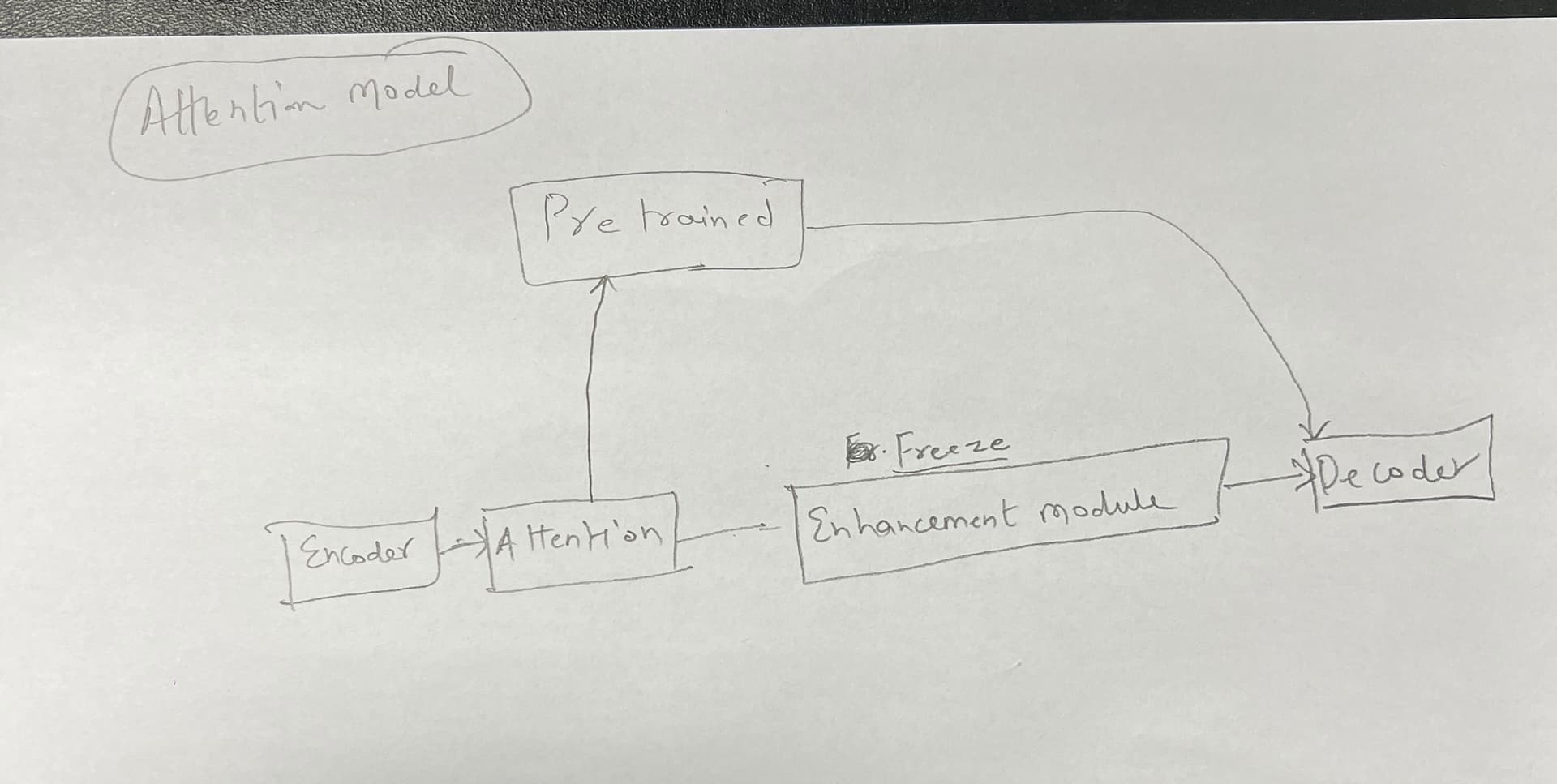
Hello everyone, I am using a pre-trained model to train our model. But I want to freeze all the parameters of the current model (the enhancement module in the picture) and only use the pretrained model. I want to see the parameters of the attention block and pretrained model. My model code is given below, and for more details, i have attached our architeture picture here:
from tokenize import group
import torch as th
from torch._C import Size
import torch.nn as nn
import os
import torch.nn.functional as F
def param(nnet, Mb=True):
“”"
Return number parameters(not bytes) in nnet
“”"
neles = sum([param.nelement() for param in nnet.parameters()])
return neles / 10**6 if Mb else neles
class ChannelWiseLayerNorm(nn.LayerNorm):
“”"
Channel wise layer normalization
“”"
def __init__(self, *args, **kwargs):
super(ChannelWiseLayerNorm, self).__init__(*args, **kwargs)
def forward(self, x):
"""
x: N x C x T
"""
if x.dim() != 3:
raise RuntimeError("{} accept 3D tensor as input".format(
self.__name__))
# N x C x T => N x T x C
x = th.transpose(x, 1, 2)
# LN
x = super().forward(x)
# N x C x T => N x T x C
x = th.transpose(x, 1, 2)
return x
class GlobalChannelLayerNorm(nn.Module):
“”"
Global channel layer normalization
“”"
def __init__(self, dim, eps=1e-05, elementwise_affine=True):
super(GlobalChannelLayerNorm, self).__init__()
self.eps = eps
self.normalized_dim = dim
self.elementwise_affine = elementwise_affine
if elementwise_affine:
self.beta = nn.Parameter(th.zeros(dim, 1))
self.gamma = nn.Parameter(th.ones(dim, 1))
else:
self.register_parameter("weight", None)
self.register_parameter("bias", None)
def forward(self, x):
"""
x: N x C x T
"""
if x.dim() != 3:
raise RuntimeError("{} accept 3D tensor as input".format(
self.__name__))
# N x 1 x 1
mean = th.mean(x, (1, 2), keepdim=True)
var = th.mean((x - mean)**2, (1, 2), keepdim=True)
# N x T x C
if self.elementwise_affine:
x = self.gamma * (x - mean) / th.sqrt(var + self.eps) + self.beta
else:
x = (x - mean) / th.sqrt(var + self.eps)
return x
def extra_repr(self):
return "{normalized_dim}, eps={eps}, " \
"elementwise_affine={elementwise_affine}".format(**self.__dict__)
def build_norm(norm, dim):
“”"
Build normalize layer
LN cost more memory than BN
“”"
if norm not in [“cLN”, “gLN”, “BN”]:
raise RuntimeError(“Unsupported normalize layer: {}”.format(norm))
if norm == “cLN”:
return ChannelWiseLayerNorm(dim, elementwise_affine=True)
elif norm == “BN”:
return nn.BatchNorm1d(dim)
else:
return GlobalChannelLayerNorm(dim, elementwise_affine=True)
class Conv1D(nn.Conv1d):
“”"
1D conv in ConvTasNet
“”"
def __init__(self, *args, **kwargs):
super(Conv1D, self).__init__(*args, **kwargs)
def forward(self, x, squeeze=False):
print(x)
"""
x: N x L or N x C x L
"""
if x.dim() not in [2, 3]:
raise RuntimeError("{} accept 2/3D tensor as input".format(
self.__name__))
x = super().forward(x if x.dim() == 3 else th.unsqueeze(x, 1))
if squeeze:
x = th.squeeze(x)
return x
class Attention(nn.Module):
def init(self, enc_dim=512):
super(Attention, self).init()
self.conv = nn.Conv1d(enc_dim, enc_dim, kernel_size=1, stride=1, padding=0, bias=False)
self.bn = nn.BatchNorm1d(enc_dim)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.softmax(x)
return x
class ConvTrans1D(nn.ConvTranspose1d):
“”"
1D conv transpose in ConvTasNet
“”"
def __init__(self, *args, **kwargs):
super(ConvTrans1D, self).__init__(*args, **kwargs)
def forward(self, x, squeeze=False):
"""
x: N x L or N x C x L
"""
if x.dim() not in [2, 3]:
raise RuntimeError("{} accept 2/3D tensor as input".format(
self.__name__))
x = super().forward(x if x.dim() == 3 else th.unsqueeze(x, 1))
if squeeze:
x = th.squeeze(x)
return x
class Conv1DBlock(nn.Module):
“”"
1D convolutional block:
Conv1x1 - PReLU - Norm - DConv + ChannelShuflle - PReLU - Norm - SConv
“”"
def __init__(self,
in_channels=256,
conv_channels=512,
groups=16,
Sc = 512,
kernel_size=3,
dilation=1,
norm="cLN",
# n_embd = 256,
n_head = 8,
causal=False):
super(Conv1DBlock, self).__init__()
# 1x1 conv nxBxT -> nXHXT
self.conv1x1 = Conv1D(in_channels, conv_channels, 1)
# self.attention = Attention(in_channels)
self.prelu1 = nn.PReLU()
self.lnorm1 = build_norm(norm, conv_channels)
dconv_pad = (dilation * (kernel_size - 1)) // 2 if not causal else (
dilation * (kernel_size - 1))
# shuflling
groups= (dilation * (kernel_size - 1)) // 2 if not causal else (
dilation* (kernel_size - 1))
# shuflling
#outchannl=(conv_channels//groups)
# shuflled conv
groupoutchnl=256
dcon_group_output= groupoutchnl+groupoutchnl
# shuflled conv
self.shuffgroupconv=nn.Conv1d(
conv_channels,
groupoutchnl,
kernel_size,
groups=groups,
padding=dconv_pad,
dilation=dilation,
bias=True)
# depthwise conv
self.tanh1 = nn.Tanh()
self.dconv = nn.Conv1d(
conv_channels,
conv_channels,
kernel_size,
groups=conv_channels,
padding=dconv_pad,
dilation=dilation,
bias=True)
self.shuffgroup=ChannelShuffle(conv_channels,groups)
self.conv1x1_2 = Conv1D(conv_channels, groupoutchnl, 1)
self.sigmoid1 = nn.Sigmoid()
#self.conv1x1_2 = Conv1D(dcon_group_output, dcon_group_output, 1)
self.prelu2 = nn.PReLU()
self.lnorm2 = build_norm(norm, groupoutchnl*2)
# 1x1 conv cross channel
self.sconv = nn.Conv1d(groupoutchnl*2, in_channels, 1, bias=True)
#1x1 conv skip-connection
self.skip_out = nn.Conv1d(groupoutchnl*2, Sc, 1, bias=True)
self.causal = causal
self.dconv_pad = dconv_pad
def forward(self, x):
y = self.conv1x1(x)
# x = self.attention(x)
if __name__ == "__main__":
print('1D blick after fist 1x1Conv size', y.size())
y = self.lnorm1(self.prelu1(y))
sh=self.shuffgroup(y)
shuffcov=self.shuffgroupconv(sh)
shufftan=self.tanh1(shuffcov)
shuffsigm=self.sigmoid1(shuffcov)
print("shape after shuffle",sh.size())
print("shape of shuffle groupe conv",shuffcov.size())
y = self.dconv(y)
y=self.conv1x1_2(y)
depsigm=self.sigmoid1(y)
deptan=self.tanh1(y)
_x_up=shufftan*depsigm
_x_down=shuffsigm*deptan
y = th.cat(( _x_up, _x_down), 1)
#y=y+shuffcov
#x_out = self.Multiply()([x_sigmoid, x_tanh])
# y = th.cat(( y, shuffcov), axis=1)
print("shape before 1x1", y.size())
# y=self.conv1x1_2(y)
# newArray= self.conv1x1(newArray)
print("shape after 1x1", y.size())
if __name__ == "__main__":
print('1D Conv block after group cov size', y.size())
if self.causal:
y = y[:, :, :-self.dconv_pad]
y = self.lnorm2(self.prelu2(y))
out = self.sconv(y)
skip = self.skip_out(y)
x = x + out
return skip, x
def channel_shuffle(x,
groups):
“”"
Channel shuffle operation from ‘ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices,’
[1707.01083] ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices.
Parameters:
----------
x : Tensor
Input tensor.
groups : int
Number of groups.
Returns
-------
Tensor
Resulted tensor.
“”"
batch, channels, height = x.size()
# assert (channels % groups == 0)
channels_per_group = channels // groups
x = x.view(batch, groups, channels_per_group, height)
x = th.transpose(x, 1, 2).contiguous()
x = x.view(batch, channels, height)
return x
class ChannelShuffle(nn.Module):
“”"
Channel shuffle layer. This is a wrapper over the same operation. It is designed to save the number of groups.
Parameters:
----------
channels : int
Number of channels.
groups : int
Number of groups.
“”"
def __init__(self,
channels,
groups):
super(ChannelShuffle, self).__init__()
# assert (channels % groups == 0)
if channels % groups != 0:
raise ValueError('channels must be divisible by groups')
self.groups = groups
def forward(self, x):
return channel_shuffleforsound(x, self.groups)
*****************************************
class MS_SL1_only_attention_model(nn.Module):
def init(self,
L=16, #length of filters(in sample)
N=512, #Number of filters in Autoencoder
X=8, #Number of convolution block in each repeat
R=1,#Number of repeats
B=128,#Number of channels in bottleneck and residual paths’ 1 by 1-conv blocks
Sc=128,# number of channels in skip-connection paths’ 1 by 1-conv blocks
Slice=1,
H=512,#Number of channel in convolution blocks
P=3, #kernal size in convolution blocks
norm=“gLN”,
num_spks=2,
non_linear=“sigmoid”,
causal=False):
super(MS_SL1_only_attention_model, self).init()
supported_nonlinear = {
“relu”: F.relu,
“sigmoid”: th.sigmoid,
“softmax”: F.softmax
}
if non_linear not in supported_nonlinear:
raise RuntimeError(“Unsupported non-linear function: {}”,
format(non_linear))
self.non_linear_type = non_linear
self.non_linear = supported_nonlinear[non_linear]
# n x S => n x N x T, S = 4s*8000 = 32000
#self.attention = Attention(N)
self.encoder_1d = Conv1D(1, N, L, stride=L // 2, padding=0)
self.attention = Attention(N)
# keep T not change
# T = int((xlen - L) / (L // 2)) + 1
# before repeat blocks, always cLN
self.ln = ChannelWiseLayerNorm(N)
# n x N x T => n x B x T
self.proj = Conv1D(N, B, 1)
# repeat blocks
# n x B x T => n x B x T
self.slices = self._build_slices(
Slice,
R,
X,
Sc=Sc,
in_channels=B,
conv_channels=H,
kernel_size=P,
norm=norm,
causal=causal)
#weight for each branch
self.wList = nn.Parameter(th.tensor([0.5+0.001, 0.5-0.001]),requires_grad=True)
self.PRelu = nn.PReLU()
# repeat blocksist not python list
# self.conv1x1_2 = th.nn.ModuleList(
# [Conv1D(B, N, 1) for _ in range(num_spks)])
# n x Sc x T => n x 2N x T
self.mask = Conv1D(Sc, num_spks * N, 1)
# using ConvTrans1D: n x N x T => n x 1 x To
# To = (T - 1) * L // 2 + L
self.decoder_1d = ConvTrans1D(
N, 1, kernel_size=L, stride=L // 2, bias=True)
self.num_spks = num_spks
self.R = R #numbers of repeat
self.X = X #numbers of Conv1Dblock in each repeat
self.slice = Slice #numbers of slices
def _build_blocks(self, num_blocks, **block_kwargs):
"""
Build Conv1D block
"""
blocks = [
Conv1DBlock(**block_kwargs, dilation=(2**b))
for b in range(num_blocks)
]
return nn.Sequential(*blocks)
def _build_repeats(self, num_repeats, num_blocks, **block_kwargs):
"""
Build Conv1D block repeats
"""
repeats = [
self._build_blocks(num_blocks, **block_kwargs)
for r in range(num_repeats)
]
return nn.Sequential(*repeats)
def _build_slices(self, num_slice, num_repeats, num_blocks, **block_kwargs):
"""
Build Conv1D block repeats
"""
slices = [
self._build_repeats(num_repeats, num_blocks, **block_kwargs)
for r in range(num_slice)
]
return nn.Sequential(*slices)
def forward(self, x):
if __name__ == "__main__":
print('input size', x.size())
if x.dim() >= 3:
raise RuntimeError(
"{} accept 1/2D tensor as input, but got {:d}".format(
self.__name__, x.dim()))
# when inference, only one utt
if x.dim() == 1:
x = th.unsqueeze(x, 0)
#encoder
# n x 1 x S => n x N x T
w = F.relu(self.encoder_1d(x))
if __name__ == "__main__":
print('after encoder size', w.size())
print('encoder sum:',sum(m.numel() for m in self.encoder_1d.parameters()))
#Seperation
# LayerNorm & 1X1 Conv
# n x B x T
w = self.attention(w)
if __name__ == "__main__":
print('after attention size', w.size())
print('attention sum:',sum(m.numel() for m in self.attention.parameters()))
y = self.proj(self.ln(w))
if __name__ == "__main__":
print('after LayerNorm and 1x1 Conv', y.size())
#Slices of TCN
# n x B x T
th.total_connection = 0
skip_connection = 0
Slice_input = y
Tcn_into_weight=[]
Tcn_output_result=0
##Tcn_output_result=th.zeros(2,128,11)
for Slice in range(self.slice):
if __name__ == "__main__":
print('slice input size', y.size())
for i in range(self.R):
for j in range(self.X):
if __name__ == "__main__":
print('1D Conv block input size', y.size())
skip, y = self.slices[Slice][i][j](y)
skip_connection = skip_connection + skip
print("Skip connection check here",skip_connection.size()),
if __name__ == "__main__":
print('finished 1D Conv block skip_connection size', skip.size())
print('finished 1D Conv block ouput size', y.size())
print("Weight lenght ",self.wList)
for i in range (len(self.wList)):
#if a==0:
print("Weight value1", self.wList[i])
total_connection = skip_connection *self.wList[i]
Tcn_into_weight.append(total_connection)
#print("the slices value to be added", total_connection)
#print("Weight value1 after append ", W_firstResult)
total_connection=0
print("Weight lenght ",len(self.wList))
if __name__ == "__main__":
print('slice weight last', self.wList[Slice-2])
skip_connection = 0
y = Slice_input
for i in range(len(Tcn_into_weight)):
print("Tcn value to be added: ",Tcn_into_weight[i])
print("existed Tcn value: ",Tcn_output_result)
Tcn_output_result+=Tcn_into_weight[i]
print("TcnResult values", Tcn_output_result)
print(" Out put of TcnResult shape", Tcn_output_result.size())
y = self.PRelu(Tcn_output_result)
print("Output of Tcn size after pRelu",y.size())
print('after tcn sum:',sum(m.numel() for m in self.PRelu.parameters()))
# n x 2N x T
e = th.chunk(self.mask(y), self.num_spks, 1)
if __name__ == "__main__":
print('after 1x1 Conv mask)', e[0].size())
# n x N x T
if self.non_linear_type == "softmax":
m = self.non_linear(th.stack(e, dim=0), dim=0)
else:
m = self.non_linear(th.stack(e, dim=0))
# spks x [n x N x T]
s = [w * m[n] for n in range(self.num_spks)]
print('end sum:',sum(m.numel() for m in self.decoder_1d.parameters()))
# spks x n x S
return [self.decoder_1d(x, squeeze=True) for x in s]
***********************************************
def foo_conv1d_block():
nnet = Conv1DBlock(256, 512, 3, 20)
print(param(nnet))
def foo_layernorm():
C, T = 256, 20
nnet1 = nn.LayerNorm([C, T], elementwise_affine=True)
print(param(nnet1, Mb=False))
nnet2 = nn.LayerNorm([C, T], elementwise_affine=False)
print(param(nnet2, Mb=False))
def SL2_split(**nnet_conf):
cpt = th.load(‘/media/speechsever/Toshibha-3.0TB/MS_R1_SL2_saved_models/best.pt.tar’)
x = th.rand(4, 1000)
# nnet = MB_ConvTasNet(norm=“cLN”, causal=False)
nnet = MS_SL1_only_attention_model(**nnet_conf)
nnet.load_state_dict(cpt[“model_state_dict”],strict=False)
#print(“model detail”, nnet)
#print(“ConvTasNet #param: {:.2f}”.format(param(nnet)))
for param in nnet.parameters():
param.requires_grad = False
for param in nnet.attention.parameters():
param.requires_grad = True
#print(“param.name”,param.data)
x = nnet(x)
test_param = {}
for name,param in nnet.named_parameters():
test_param[name] = param.detach().cpu().numpy()
print(“123test”,test_param)
s1 = x[0]
print(s1.shape)
if name == “main”:
SL2_split()
Thank you so much