Hi! This is my vit code and I can run it on 2 GPUs using DDP. But when I use FSDP to package it, it fails.
import os
import math
import argparse
import torch
import torch.optim as optim
import torch.optim.lr_scheduler as lr_scheduler
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from my_dataset import MyDataSet
from vit_model import vit_base_patch16_224_in21k as create_model
from utils import read_split_data, train_one_epoch, evaluate
# 新增1:依赖
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
def main(args):
local_rank = args.local_rank
# 新增3:DDP backend初始化
# a.根据local_rank来设定当前使用哪块GPU
# torch.cuda.set_device(local_rank)
torch.cuda.set_device('cuda:' + local_rank)
# b.初始化DDP,使用默认backend(nccl)就行。如果是CPU模型运行,需要选择其他后端。
dist.init_process_group(backend='nccl')
# 新增4:定义并把模型放置到单独的GPU上,需要在调用`model=DDP(model)`前做哦。
# 如果要加载模型,也必须在这里做哦。
device = torch.device("cuda:" + local_rank)
# device = torch.device(args.device if torch.cuda.is_available() else "cpu")
if os.path.exists("./weights") is False:
os.makedirs("./weights")
tb_writer = SummaryWriter()
train_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path)
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])}
# 实例化训练数据集
train_dataset = MyDataSet(images_path=train_images_path,
images_class=train_images_label,
transform=data_transform["train"])
# 实例化验证数据集
val_dataset = MyDataSet(images_path=val_images_path,
images_class=val_images_label,
transform=data_transform["val"])
batch_size = args.batch_size
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
# 新增1:使用DistributedSampler,DDP帮我们把细节都封装起来了。用,就完事儿!
# sampler的原理,后面也会介绍。
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
val_sampler = torch.utils.data.distributed.DistributedSampler(val_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
pin_memory=True,
num_workers=nw,
collate_fn=train_dataset.collate_fn,
sampler=train_sampler)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=batch_size,
pin_memory=True,
num_workers=nw,
collate_fn=val_dataset.collate_fn,
sampler=val_sampler)
model = create_model(num_classes=5, has_logits=False).to(device)
model = DDP(model, device_ids=[int(local_rank)], output_device=int(local_rank),find_unused_parameters=True)
model = FSDP(model)
if args.weights != "":
assert os.path.exists(args.weights), "weights file: '{}' not exist.".format(args.weights)
weights_dict = torch.load(args.weights, map_location=device)
# 删除不需要的权重
del_keys = ['head.weight', 'head.bias'] if model.has_logits \
else ['pre_logits.fc.weight', 'pre_logits.fc.bias', 'head.weight', 'head.bias']
for k in del_keys:
del weights_dict[k]
print(model.load_state_dict(weights_dict, strict=False))
if args.freeze_layers:
for name, para in model.named_parameters():
# 除head, pre_logits外,其他权重全部冻结
if "head" not in name and "pre_logits" not in name:
para.requires_grad_(False)
else:
print("training {}".format(name))
pg = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.SGD(pg, lr=args.lr, momentum=0.9, weight_decay=5E-5)
# Scheduler https://arxiv.org/pdf/1812.01187.pdf
lf = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - args.lrf) + args.lrf # cosine
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
for epoch in range(args.epochs):
train_loader.sampler.set_epoch(epoch)
# train
train_loss, train_acc = train_one_epoch(model=model,
optimizer=optimizer,
data_loader=train_loader,
device=device,
epoch=epoch)
scheduler.step()
# validate
val_loss, val_acc = evaluate(model=model,
data_loader=val_loader,
device=device,
epoch=epoch)
tags = ["train_loss", "train_acc", "val_loss", "val_acc", "learning_rate"]
tb_writer.add_scalar(tags[0], train_loss, epoch)
tb_writer.add_scalar(tags[1], train_acc, epoch)
tb_writer.add_scalar(tags[2], val_loss, epoch)
tb_writer.add_scalar(tags[3], val_acc, epoch)
tb_writer.add_scalar(tags[4], optimizer.param_groups[0]["lr"], epoch)
torch.save(model.state_dict(), "./weights/model-{}.pth".format(epoch))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--num_classes', type=int, default=5)
parser.add_argument('--epochs', type=int, default=10)
parser.add_argument('--batch-size', type=int, default=8)
parser.add_argument('--lr', type=float, default=0.001)
parser.add_argument('--lrf', type=float, default=0.01)
parser.add_argument('--data-path', type=str,
default="../flower_photos")
parser.add_argument('--model-name', default='', help='create model name')
parser.add_argument('--weights', type=str, default='',
help='initial weights path')
parser.add_argument('--freeze-layers', type=bool, default=True)
parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)')
parser.add_argument("--local_rank", default=-1)
opt = parser.parse_args()
main(opt)
To run this code, you need to set up a data file, which is like:
├── flower_photos
└──vision_transformer
…└── train.py
And the flower_photos data is from: [https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz]
Just uncompress it is enough.
I meet this bug:
ValueError: optimizer got an empty parameter list
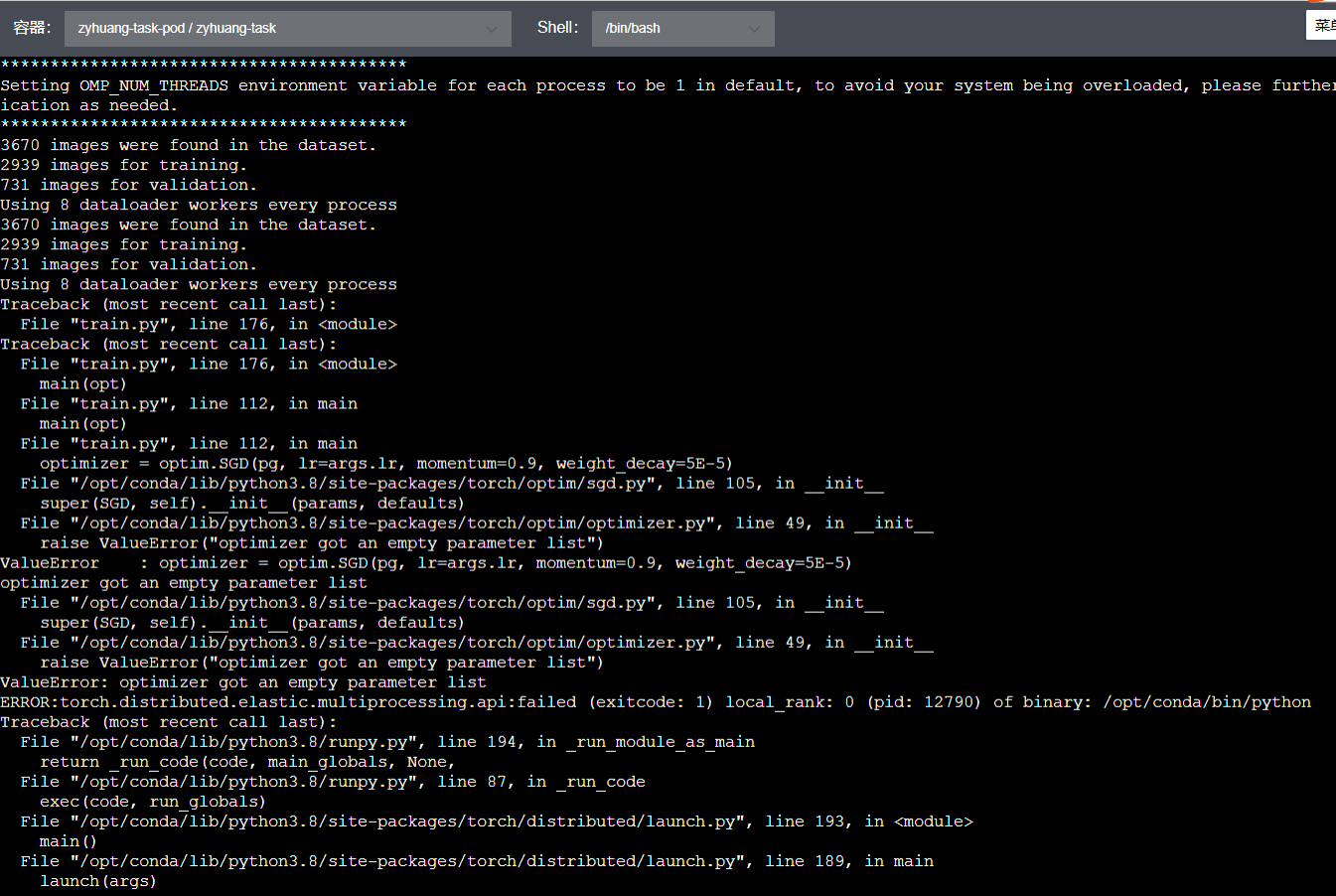
Thank you!!!