Hello everyone, I’ve been reading the FSDP paper and the tutorials and have a couple of questions I could use some help with.
My understanding is FSDP does the forward pass of each FSDP Unit, one at a time, then it does the backprop again one at a time, and finally it updates weights. Both in the forward and backward of a given FSDP Unit all the sharded parameters for that unit are fully materialized for a moment and then discarded when no longer needed.
-
If all the weights of an FSDP unit are fully materialized, why even bother using a sharding factor F > 1? Why can’t we just always replicate all the weights of the unit in all GPUs since we know it will fit?
-
Initially before the process begins are all shards stored in CPU and each FSDP unit is sent to the GPU one at a time and then back to CPU?
-
After backprop for all layers, how are the parameters of the shards updated? Does PyTorch iterate again across all shards and update one at a time in a loop?
-
Finally, the diagram that is shown in all the tutorials is not making sense for me. It looks like that the first FSDP Unit of layers 1:N is processed with forward and then backward, and then (all the way to the right of the image) the algorithm moves to the next FSDP Unit where it does forward and backward again. I don’t think this makes sense, since we need to do full forward of all layers first before doing backprop over all layers. Perhaps I’m misunderstanding something?
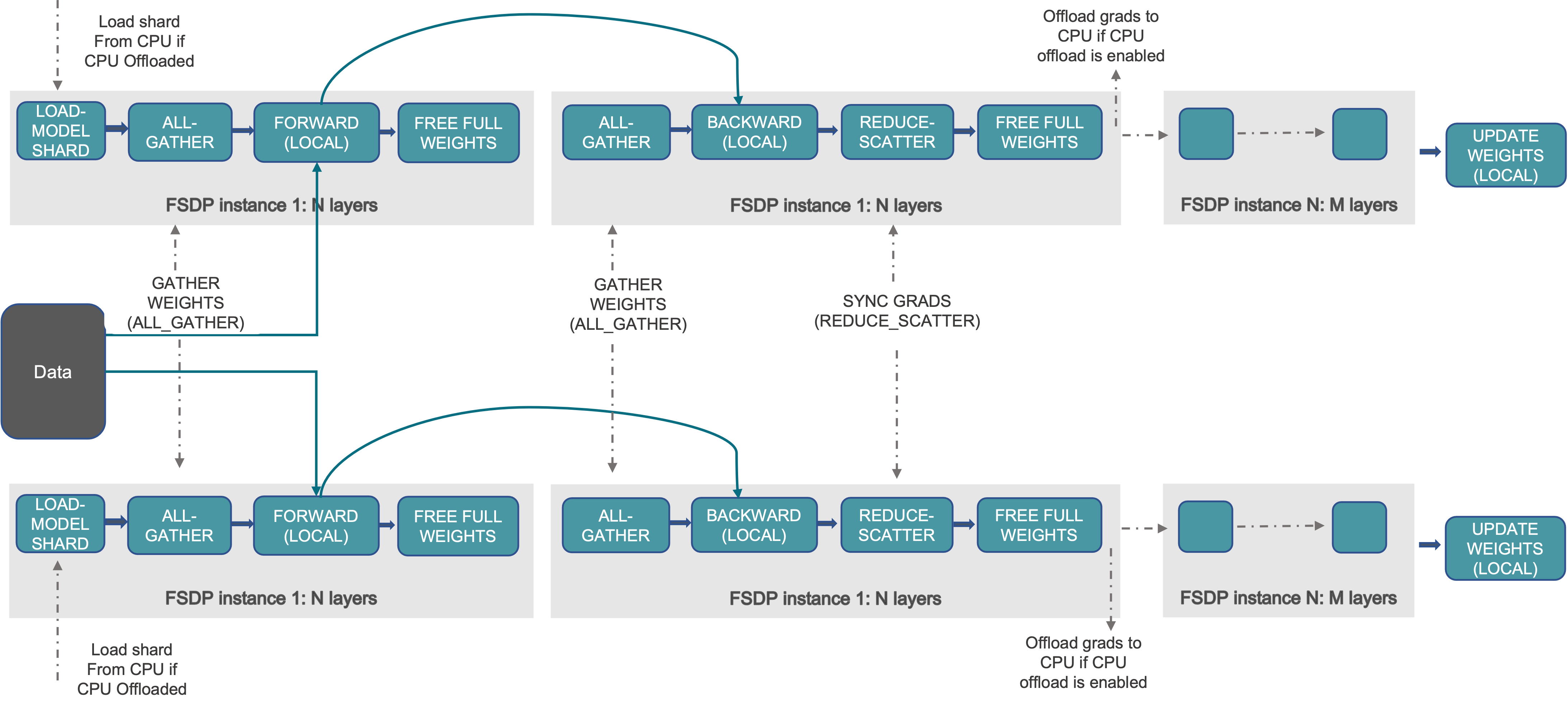
Thanks !!