hi,
I use FSDP to train model with 1k gpus, I found some ranks are slow and make all ranks slow down.
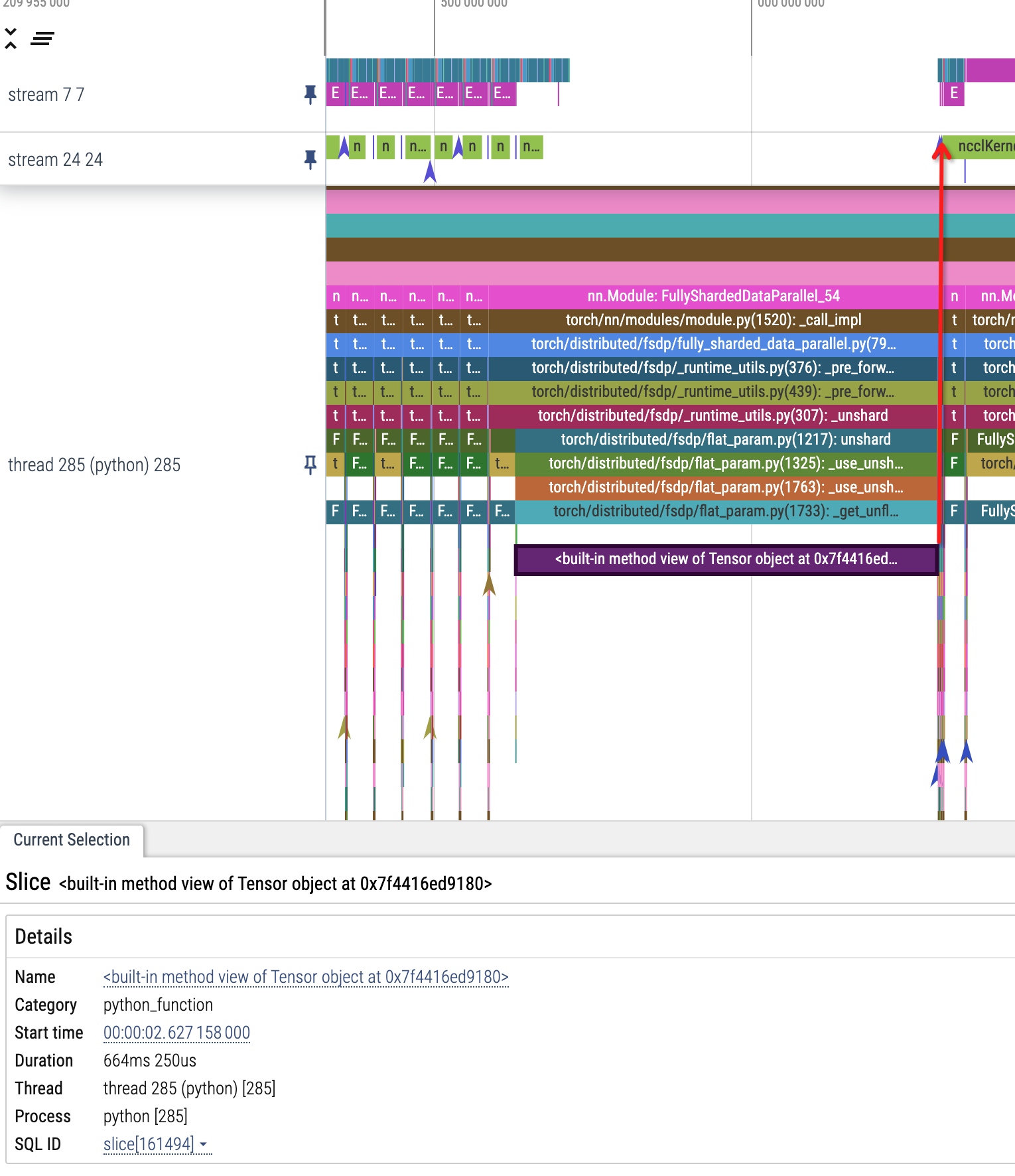
I have some trace described as below, the view op in FSDP’s unshard is blocking the all gather kernel, it let others have to wait it.
But view op only change strides of tensor, it is very fast, how it happens? Does pytorch has other threads in main python progress?