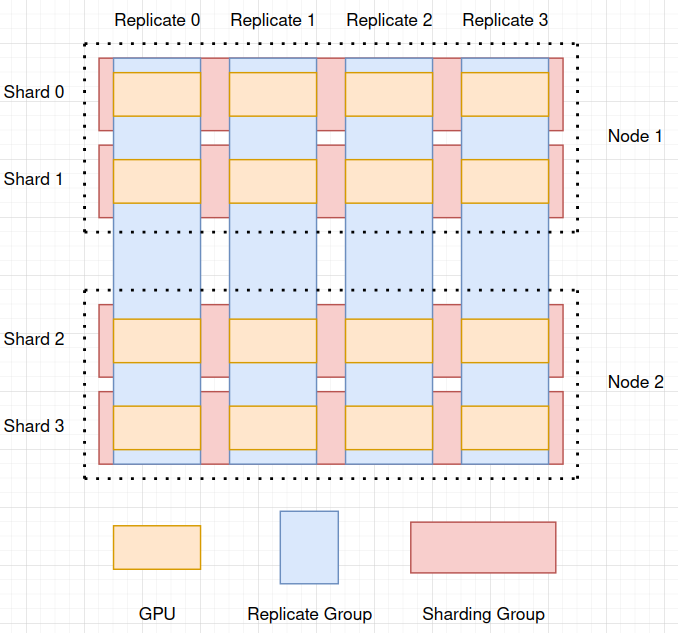
Sharding within a node but only to a limited number of devices
For example, if we had 2 nodes with 8 GPUs each, I’d like to have FSDP/HSDP with 4GPUs for sharding and 4 replicas (2 within a node). I’d assume that setting device_mesh to 4x4 would (maybe?) do this. So, my question is the following I guess:
Is it guaranteed to init sharding within a node first if I create a device mesh, i.e. sharding inter nodes is avoided?
When you create a 2D DeviceMesh and pass it to HSDP, it always assumes the outer dimension is the replicate group and the inner dimension is the shard group. Under the hood, it is just using the process group (code pointer here: pytorch/torch/distributed/fsdp/_init_utils.py at main · pytorch/pytorch · GitHub). DeviceMesh is just helping initialize the process group easily.
Sorry, just for clarification as I’m not familiar with the device mesh initialization (/abstraction), I’d expand on my example. Assuming I have node 1 with ranks 0 to 7 (8 in total) and node 2 with ranks 8 to 15 (also 8 in total), I’d then expect with a (4,4) device mesh to get the following pgs: