I’m trying to decrease my model GPU memory footprint to train using high-resolution medical images as input. I’m following the FSDP tutorial but am seeing an increase in GPU memory when moving to multiple GPUs rather than a decrease.
I’m using the code as-is from the FSDP tutorial except for the following changes:
I passed the custom auto_wrap policy to FSDP initialisation as it was created in the example code but not used: model = FSDP(model, auto_wrap_policy=my_auto_wrap_policy).
I update WORLD_SIZE to the number of GPUs I’d like to test on (1 or 2).
When training with a single GPU, memory usage is at 1985MiB. However, when training with 2 GPUs, memory usage for each GPU is > 2000 MiB. Any suggestions?
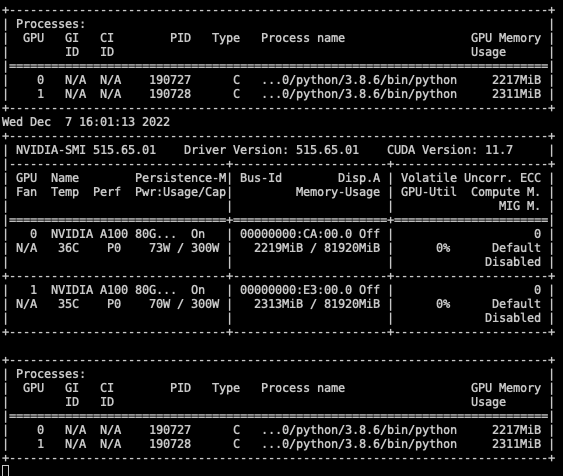
> python -m torch.utils.collect_env
Collecting environment information...
PyTorch version: 1.13.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Red Hat Enterprise Linux Server release 7.9 (Maipo) (x86_64)
GCC version: (GCC) 10.2.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.17
Python version: 3.8.6 (default, Mar 29 2021, 14:28:48) [GCC 10.2.0] (64-bit runtime)
Python platform: Linux-3.10.0-1160.66.1.el7.x86_64-x86_64-with-glibc2.2.5
Is CUDA available: True
CUDA runtime version: 11.7.64
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA A100 80GB PCIe
GPU 1: NVIDIA A100 80GB PCIe
Nvidia driver version: 515.65.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.3
[pip3] pytorch-lightning==1.8.3
[pip3] torch==1.13.0
[pip3] torchio==0.18.84
[pip3] torchmetrics==0.9.3
[pip3] torchvision==0.14.0
[conda] Could not collect
Unfortunately using nvidia-smi for verifying memory used by tensors is a bit tricky as really what is being reported is the total amount of memory being held by the caching allocator (which may be holding on to more than what is needed to speed up future allocations) as well as memory used by kernel code in libraries such as cuDNN/cuBLAS/aten, etc. To get a more accurate picture, could you check if e.g., the actual allocated memory is also increasing (e.g., via torch.cuda.memory_allocated — PyTorch 1.13 documentation) ?
Thanks for the insight, I’ve checked the tensor allocated memory during the training loop and see:
For a single GPU: ~ 23MB
For 2 GPUs: ~ 12 MB.
This seems to me like the FSDP is working correctly. This value seems much lower than the nvidia-smi readout (showing ~ 2500MB for either 1 or 2 GPUs). I’m running the FSDP MNIST tutorial example with a batch size of 1024 for both training and testing on A100 GPUs. Should the nvidia-smi readout be this high?
I believe ~1GiB or more could simply be because of the library sizes these days. If you want to force the caching allocator to release unused memory, you could see if torch.cuda.empty_cache() reduces the amount reported by nvidia-smi if it is called right after (of course running the training loop would cause the caching allocator to reserve more memory, even if it is not needed immediately). Note that this would just confirm that the allocator is indeed holding onto a significant amount of memory rather than “leaking” it somehow.
Alternatively, you could check the sizes occupied by libraries with a few trivial calls, e.g., allocate a single 1x1 tensor and use it for a convolution and matmul and check the memory usage afterwards—that should give you a rough estimate of the memory occupied by the CUDA context + cuBLAS + cuDNN without much being used by the caching allocator.
I am wondering for your actual application (not the tutorial), what is your target model size/structure, and also how large the inputs? For example, if your model size is not that large, but the input size is large (since they are high resolution), activation checkpointing may be more helpful than FSDP, which does not target activation memory.
I think this is a very good point, I would expect the activations to use a lot of memory. My input size is very large, the input is a large single-channel 3D image, with dimensions 340 x 205 x 180 and I would like to increase this size. The model is rather small (~90M parameters).
My other question is that wouldn’t a large input size also translate to large footprint for storing gradients? As FSDP shards gradients, I would have expected to see a decrease even without activation sharding.
Regardless, I’ll add activation sharding and see if it makes any difference.
Re my last question - I’m guessing that pytorch stores a gradient value per model parameter. So if a parameter is responsible for many activations (e.g. convolution weight), the partial gradients from each activation are summed to produce a single value and the partial gradients are discarded.
In this way, the number of gradient values would be equal to the number of model parameters (~90M) while the number of activations depends on the input size and could be much larger. Is this your thinking?
Yes, PyTorch accumulates the partial gradients into a single tensor, and what you are saying aligns with my thinking.
If your model is only ~90M parameters, then DistributedDataParallel should suffice. The gradients have the same size as the parameters, so those will still be pretty small.
I am not sure what optimizer you are using, but say you are using something like Adam that stores two optimizer states per parameter. Then, for a 90M parameter model, you have 90 * 1e6 * 4 * 4 bytes =1.44 * 1e9 bytes =1.44 GB. (The first 4 comes from 4 bytes per element, and the second 4 comes from 1 for the parameter element, 1 for the gradient, and 2 for the optimizer states, summed together.)
This means that if you have W GPUs, then at best with FSDP, you still need 1.44 / W GB per rank (in practice, FSDP cannot perfectly divide by W). For example, if you have 8 GPUs, then you are only saving 1.26 GB at best, which is not that significant when you are activations may be in the tens of GB depending on the batch size.
Activation checkpointing showed the best GPU memory reduction (~40%) for this application with large input sizes (medical image segmentation). FSDP wasn’t beneficial due to the small number of parameters/gradients.